큰 사이즈 데이터로부터 유의미한 지표를 분석해내는 것.
- 정의
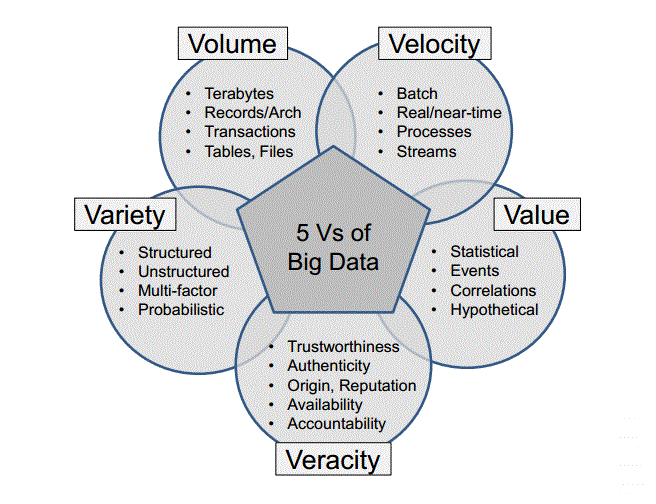
- 데이터 규모
- 기존 DB의 수집, 저장, 관리, 분석 역량에 넘어서는 데이터
- 업무 수행 방식
- 대규모 데이터로부터 가치를 추출
- 데이터의 빠른 수집, 발굴, 분석을 지원
- 데이터 규모
- 특징
- Volume
- Variety
- 정형, 반정형, 비정형 데이터 분석
- Velocity
- 실시간 데이터 처리. 배치 처리.
- Value
- 유의미한 가치
- Veracity
- 데이터의 신뢰성, 정확성
- 데이터가 많을수록 더 정확한 분석.
- 처리단계
- 수집
- 데이터 수집
- 정제
- 필요없는 데이터, 깨진 데이터 정리.
- 적재
- 정제된 데이터를 RDB, NoSQL, Druid 등에 적재
- 분석
- 의미있는 지표로 분석
- 시각화
- 분석한 결과를 보여줌.
- 수집

- Flume
- 클라우데라에서 개발한 서버 로그 수집 도구.
- 각 서버에 에이전트가 있으며, 에이전트로부터 데이터를 전달 받는 콜렉터로 구성.
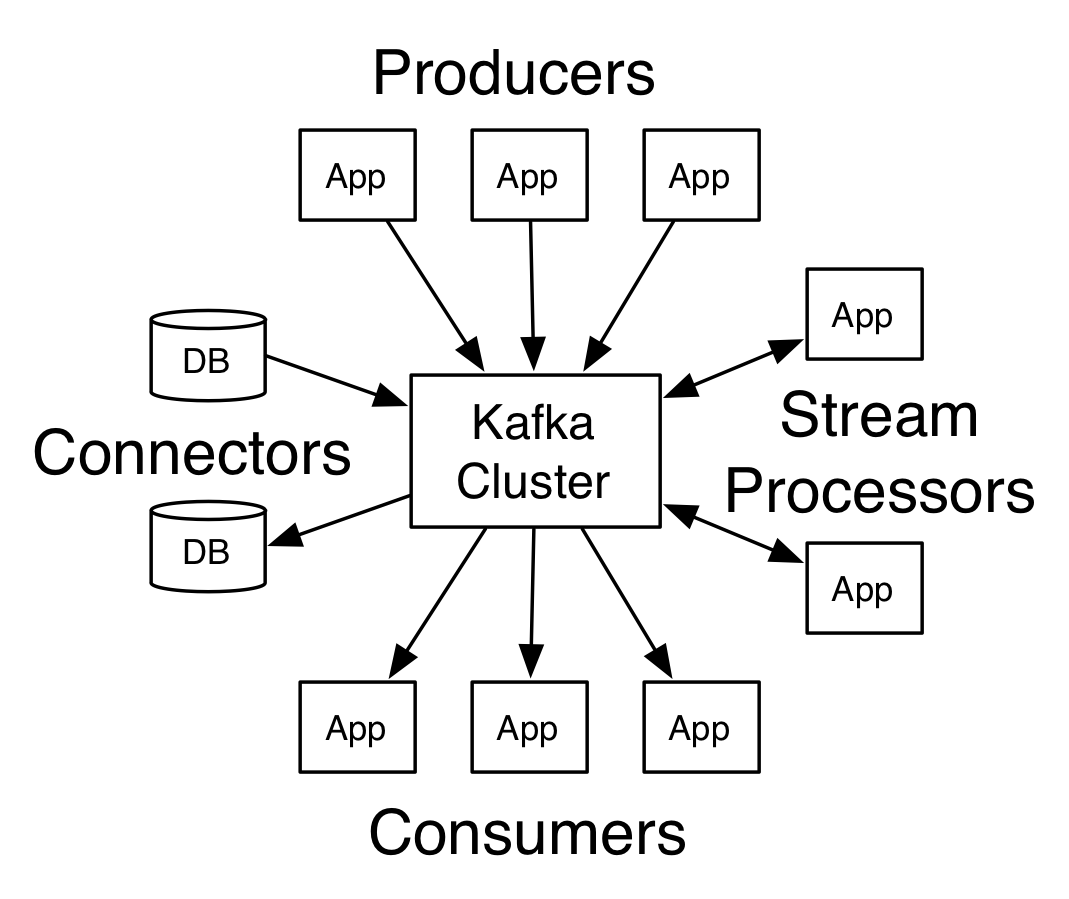
- Kafka
- 링크드인에서 개발한 분산 메시징 시스템.
- 대용량 실시간 로그 처리에 특화.
- publish - subscribe 모델로 구성.
- NiFi
- NSA에서 개발한 시스템 간 데이터 전달을 효율적으로 처리, 관리, 모니터링하기 위한 시스템.
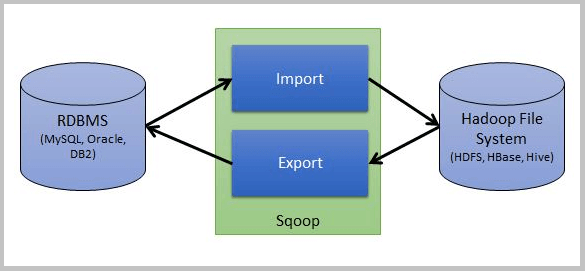
- Sqoop
- RDBMS와 HDFS간 대용량 데이터 전송을 위한 솔루션.
- HDFS, RDBMS, DW, NoSQL 등 다양한 저장소에 대용량 데이터를 신속하게 전송.
- 상용RDBMS도 지원하고, MYSQL, PostgreSQL 오픈 소스 RDBMS도 지원.


- Airflow
-
-
에어비앤비에서 개발한 데이터 흐름의 시각화, 스케쥴링, 모니터링이 가능한 workflow 플랫폼.
-
HIVE, PRESTO, DBMS 엔진과 결합하여 사용 가능.
-
- Azkaban
- 링크드인에서 개발한 workflow 스케쥴러, 시각화된 절차, 인증 및 권한관리, 작업 모니터링 및 알람 등의 기능을 가짐.
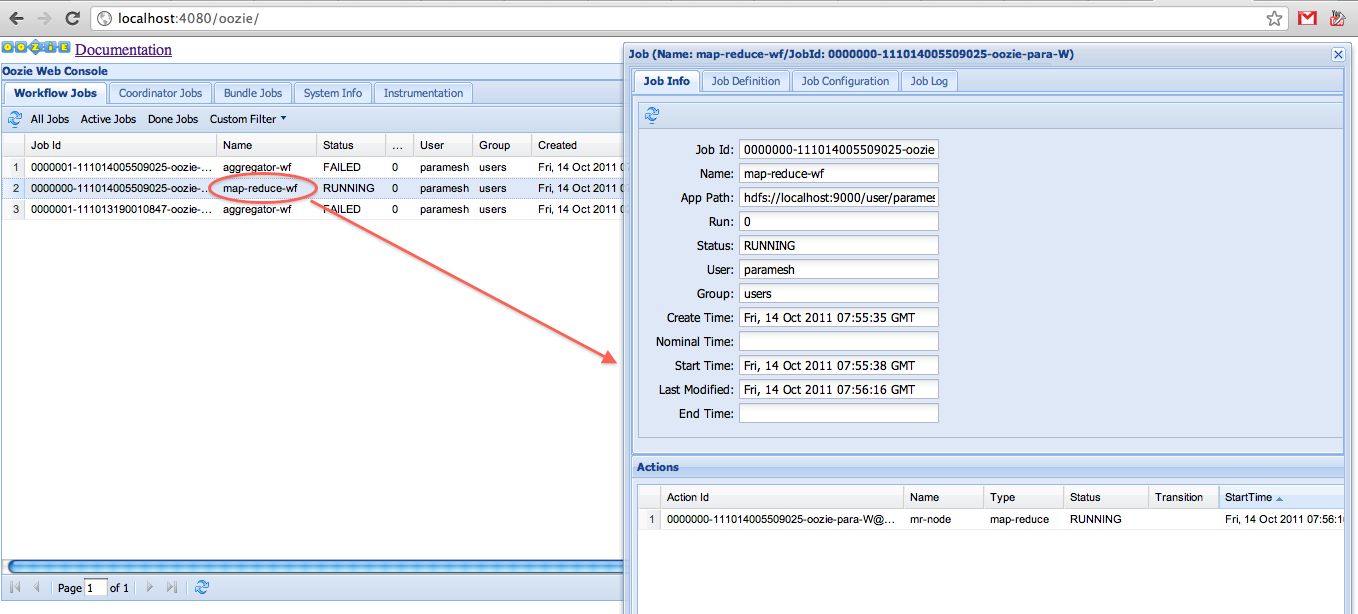
- Oozie
- 하둡 작업을 관리하는 workflow 및 cordinator 시스템.
- 자바 웹 UI제공, MR, HIVE, PIG 작업에 특화.
- XML 포맷으로 workflow 작업 제어.
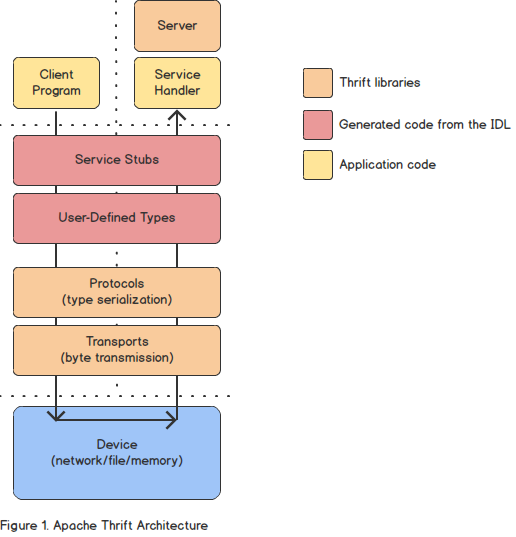
각 언어간에 내부 객체를 공유하는 경우 데이터 직렬화기술을 사용.
- Avro
- 원격 프로시저 호출(RPC) 및 데이터 직렬화 프레임워크.
- 자료형과 프로토콜 정의를 위해 JSON을 사용.
- compact binary format으로 데이터를 직렬화.
- Thrift
- 페이스북에서 개발한 다양한 언어로 개발된 모듈의 통합을 지원하는 RPC 프레임워크.
- 데이터 타입, 서비스 인터페이스를 선언하면 RPC 형태의 클라이언트와 서버 코드를 자동으로 생성.
- Protocol Buffers
- 구글에서 개발한 RPC 프레임워크.
- 구조화된 데이터를 직렬화하는 방식 제공.
- 직렬화 속도가 빠르고 직렬화된 파일의 크기도 작아서 Avro 파일 포맷과 함께 사용.
//polyline.proto syntax = "proto2"; message Point { required int32 x = 1; required int32 y = 2; optional string label = 3; }

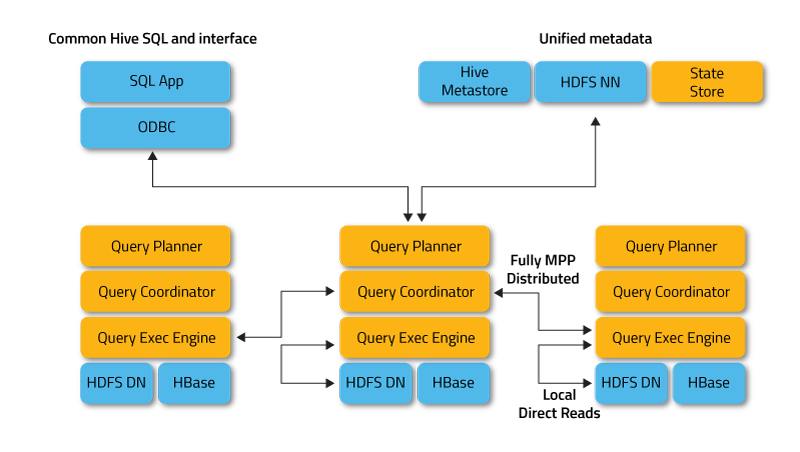
- HDFS
- 자바 언어로 작성된 분산 확장 파일 시스템.
- 범용 클러스터로 구성하여 대용량의 파일을 블록단위로 분할하여 여러서버에 복제하여 저장.
- S3
- 아마존에서 제공하는 저장소.
- MapReduce
- HDFS상에서 동작하는 가장 기본적인 처리방법.
- 단위작업을 반복할 때 효율적인 맵리듀스 모델을 이용하여 분석.
- Spark
- 인메모리 기반의 범용 데이터 처리 플랫폼
- 배치 처리, 머신러닝, SQL, 스트리밍 처리, 그래프와 같은 다양한 작업 가능.
- Impala
- 클라우데라에서 개발한 하둡 기반의 분산 쿼리 엔진
- C++로 개발한 인메모리 엔진을 사용해 빠른 성능을 보임.
- Presto
- 페이스북이 개발한 대화형 질의 처리를 위한 분산 쿼리 엔진.
- 메모리 기반으로 데이터 처리.
- Hive
- 페이스북이 개발한 하둡 기반의 데이터웨어하우징용 솔루션.
- HiveQL을 사용하며, 내부적으로 MR 잡으로 변환되어 실행됨.
- Hcatalog
- Pig, MR, Spark에서 Hive 메타스토 테이블에 액세스 할 수 있도록하는 도구.
- 테이블 생성 및 기타 작업을 REST 인터페이스, cli를 통해 제공.
- HBase
- HDFS의 컬럼 기반 데이터 베이스.
- 구글의 BigTable 논문 기반으로 개발.
- 실시간 랜덤 조회 및 업데이트가 가능.
- 각 프로세스는 개인의 데이터를 비동기적으로 업데이트.
- Pig
- Pig Latin이라는 자체 언어를 제공
- MR API를 매우 단순화한 형태이고 SQL과 유사한 형태로 설계




빅데이터는 클러스터로 처리되기 때문에 자원의 효율적인 사용이 필요.
- YARN
- 데이터 처리 작업을 실행하기 위한 클러스터 자원(CPU, 메모리, 디스크 등)과 스케쥴링을 위한 프레임워크.
- MR, Hive, Impala, Tajo, Spark 등 다양한 app이 Yarn에서 리소스 할당받아 작업을 실행.
- Mesos
- 클라우드 infra structure 및 computing engine의 다양한 자원(CPU, 메모리, 디스크)를 통합적으로 관리할 수 있도록 만든 자원 관리 프로젝트.
- 동적으로 자원을 할당하고 격리해주는 매커니즘ㅇ르 제공.
- 분산 환경에서 작업 실행을 최적화.
- 하둡, spark, storm, elasticsearch, cassandra, jenkins 등을 지원.


하나의 서버에서 모든 작업이 진행되면 해당 서버가 단일실패지점(SPOF)가 됨. 이런 리스크를 줄이기 위해 분산 서버 관리 기술을 이용.
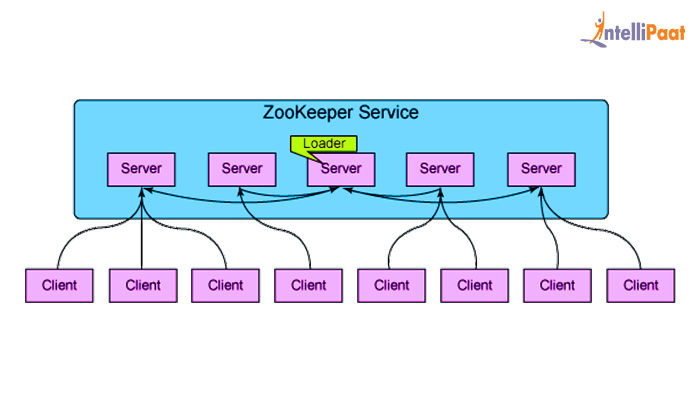
- Zookeeper
- 분산 환경에서 서버 간의 상호 조정이 필요한 다양한 서비스를 제공하는 시스템.
- 하나의 서버에만 서비스가 집중되지 않게 분산.
- 하나의 서버에서 처리한 결과를 다른 서버와도 동기화해 데이터의 안정성을 보장.
- active 서버에 문제가 발생한 경우, 대기 중인 서버를 active로 바꿔서 서비스 중지 없이 제공.
- 분산 환경을 구성하는 서버의 환경설정 관리.
- Zeppelin
- NFLab 회사에서 개발한 오픈 소스 솔루션.
- Notebook이라고 하는 웹 기반 Workspace에 Spark, Tajo, Hive, ElasticSearch 등 다양한 솔루션의 API, QUERY등을 실행하고 결과를 웹에 나타내는 솔루션.
- Hue
- 하둡과 하둡 에코시스템의 지원을 위한 웹 interface 제공.
- Hive 쿼리를 실행하는 인터페이스 제공.
- 시각화를 위한 도구 제공.
- Job Scheduling을 위한 interface
- Job, HDFS 등 하둡을 모니터링하기 위한 인터페이스도 제공.
