This repository was archived by the owner on Aug 6, 2025. It is now read-only.
This repository was archived by the owner on Aug 6, 2025. It is now read-only.
Unexpected language combinations #190
Description
I just looked at http://data.statmt.org/cc-matrix/, and the availablility/unavailability of certain language combinations is so unexpected, it almost certainly points to deep flaws in the pipeline that produced them.
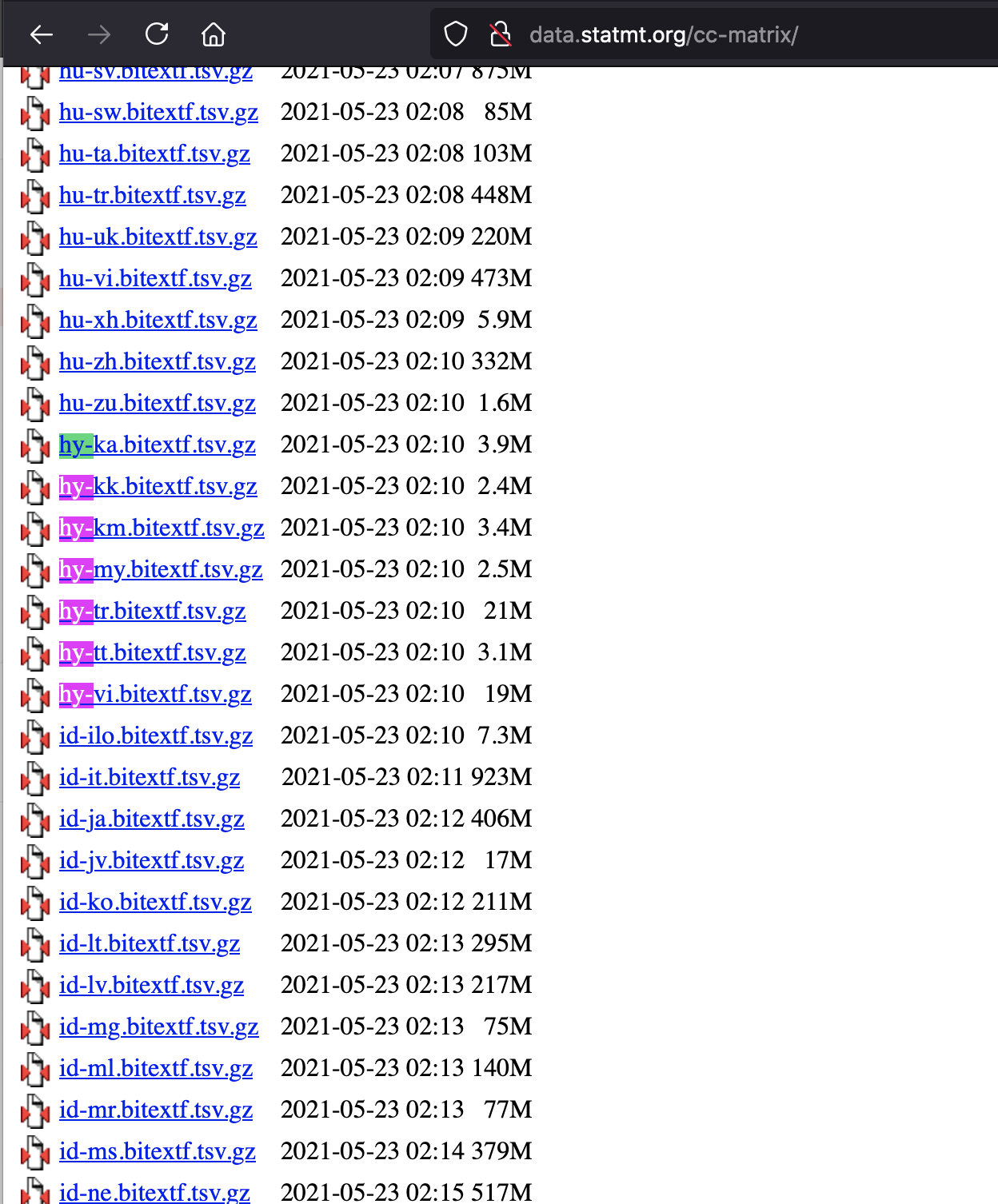
So if we pick a random medium-resource language, like Armenian, we find that there is no Armenian-English nor Armenian-Russian (nor -French, -German, -Spanish...) where we would expect a lot of parallel data.
But there is Armenian-Burmese and Armenian-Khmer, which seems unlikely given that they are very low-resource languages, and have zero contact or cultural overlap or bureacratic overlap (e.g. Council of Europe, Eurovision, CIS...).
In fact, all the pairings of Burmese my and Khmer km are unlikely and suspicious.