Connect: Envoy sidecars enter state where they fail to receive xds updates from Consul #10563
Description
Overview of the Issue
We are experiencing issues with reliability in Consul Connect, specifically around connection and CDS issues, where for some reason, intermittently, Envoy sidecars (deployed with the sidecar_service stanza in Nomad) enter an unrecoverable state where they no longer receive cluster updates from Consul.
You can see some of this in #10213, and I've provided some detail there I'm copying here.
Essentially the only fix for this currently is to restart either Envoy sidecar itself, or the Nomad allocation (which then cycles the sidecar).
Reproduction Steps
Unable to do so at this time, however, it consistently happens at random times throughout the day.
Consul info for both Client and Server
Client info
$ consul info
agent:
check_monitors = 1
check_ttls = 39
checks = 159
services = 123
build:
version = 1.10.0
consul:
acl = disabled
known_servers = 3
server = false
runtime:
arch = amd64
cpu_count = 12
goroutines = 2096
max_procs = 12
os = linux
version = go1.16.5
serf_lan:
coordinate_resets = 0
encrypted = false
event_queue = 0
event_time = 106
failed = 0
health_score = 0
intent_queue = 0
left = 0
member_time = 67643
members = 230
query_queue = 0
query_time = 4
Server info
~# consul info
agent:
check_monitors = 1
check_ttls = 0
checks = 5
services = 4
build:
version = 1.10.0
consul:
acl = disabled
bootstrap = false
known_datacenters = 4
leader = false
leader_addr = 10.133.0.146:8300
server = true
raft:
applied_index = 322772439
commit_index = 322772439
fsm_pending = 0
last_contact = 32.532339ms
last_log_index = 322772440
last_log_term = 475
last_snapshot_index = 322768509
last_snapshot_term = 475
latest_configuration = [{Suffrage:Voter ID:a6f23f31-d2a8-239d-401b-57d54a7521f9 Address:x.x.x.x:8300} {Suffrage:Voter ID:f6f24d3e-352e-ce6a-f5a7-1dc5ad5ad4d5 Address:10.133.0.147:8300} {Suffrage:Voter ID:3ddfa25a-fd64-ceee-ae54-f89e24c1ce70 Address:10.133.0.145:8300}]
latest_configuration_index = 0
num_peers = 2
protocol_version = 3
protocol_version_max = 3
protocol_version_min = 0
snapshot_version_max = 1
snapshot_version_min = 0
state = Follower
term = 475
runtime:
arch = amd64
cpu_count = 2
goroutines = 4996
max_procs = 2
os = linux
version = go1.16.5
serf_lan:
coordinate_resets = 0
encrypted = false
event_queue = 0
event_time = 109
failed = 0
health_score = 0
intent_queue = 0
left = 3
member_time = 137323
members = 233
query_queue = 0
query_time = 1
serf_wan:
coordinate_resets = 0
encrypted = false
event_queue = 0
event_time = 1
failed = 0
health_score = 0
intent_queue = 0
left = 0
member_time = 6923
members = 12
query_queue = 0
query_time = 1
Operating system and Environment details
Debian Buster:
# cat /etc/debian_version
10.10
Docker:
# docker -v
Docker version 20.10.7, build f0df350
Nomad:
# nomad -v
Nomad v1.1.2 (60638a086ef9630e2a9ba1e237e8426192a44244)
Envoy:
# envoy --version
envoy version: 98c1c9e9a40804b93b074badad1cdf284b47d58b/1.18.3/Clean/RELEASE/BoringSSL
Summary
We'll see this in a specific Envoy sidecar on a Nomad Client. For this detail, we'll say Service A (svc-a) is talking to Service B (svc-b). IPs/names are redacted here but we can provide more info securely via email.
This will start out with some connection failures:
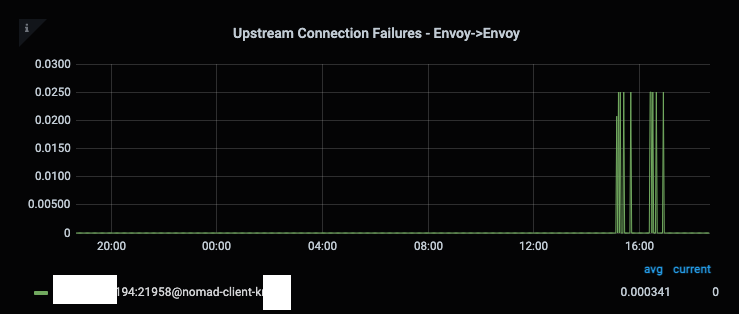
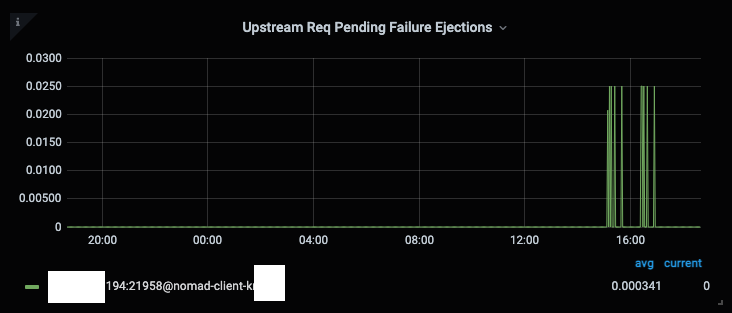
specifically, pending failure ejections:
Then transition to 5xx outlier ejections (expectedly):
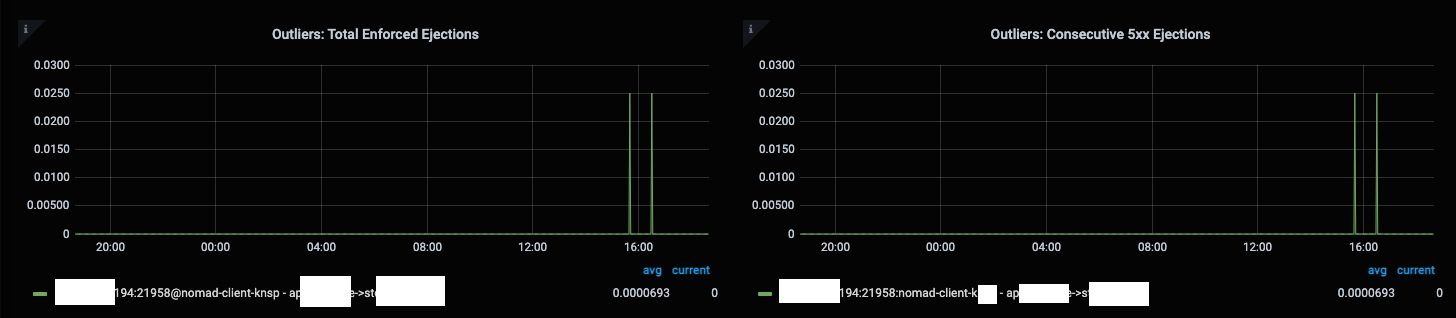
This results in all outbound connections failing with no healthy hosts errors.
Statistics
From the egress sidecar, you can see the connection failures:
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.upstream_cx_connect_fail: 26
# ...
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.outlier_detection.ejections_active: 0
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.outlier_detection.ejections_consecutive_5xx: 5
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.outlier_detection.ejections_detected_consecutive_5xx: 5
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.outlier_detection.ejections_detected_consecutive_gateway_failure: 5
Eventually this will turn into active ejections, and failures. Nomad or Consul for some reason will not mark the sidecar as unhealthy, and the service will continue to serve failing traffic until restarted.
LDS Update Failures
Looking into CDS updates, we can see that one of the clusters is unhealthy:
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.membership_change: 12
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.membership_degraded: 0
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.membership_excluded: 0
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.membership_healthy: 1
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.membership_total: 2
We have a tool we built to inspect Envoy's clusters endpoint, and (ip ranges redacted except last 2). This looks at the /clusters endpoint and aggregates our Envoy's cluster info on the svc-b upstream:
---------------------
- Cluster Instances -
---------------------
HOST | CX ACTIVE | CX FAILED | CX TOTAL | REQ ACTIVE | REQ TIMEOUT | REQ SUCCESS | REQ ERROR | REQ TOTAL | SUCCESS RATE | LOCAL SUCCESS RATE | HEALTH FLAGS | REGION | ZONE | SUBZONE | CANARY
----------------------+-----------+-----------+----------+------------+-------------+-------------+-----------+-----------+--------------+--------------------+--------------------+--------+------+---------+---------
xx.xx.64.88:21936 | 0 | 27 | 30 | 0 | 0 | 6 | 27 | 6 | -1.0 | -1.0 | healthy | | | | false
xx.xx.64.194:21753 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1.0 | -1.0 | /failed_eds_health | | | | false
Note here the failed_eds_health. However, in other sidecars with the same svc-b upstream:
---------------------
- Cluster Instances -
---------------------
HOST | CX ACTIVE | CX FAILED | CX TOTAL | REQ ACTIVE | REQ TIMEOUT | REQ SUCCESS | REQ ERROR | REQ TOTAL | SUCCESS RATE | LOCAL SUCCESS RATE | HEALTH FLAGS | REGION | ZONE | SUBZONE | CANARY
----------------------+-----------+-----------+----------+------------+-------------+-------------+-----------+-----------+--------------+--------------------+--------------+--------+------+---------+---------
xx.xx.64.88:23637 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1.0 | -1.0 | healthy | | | | false
xx.xx.64.194:23829 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | -1.0 | -1.0 | healthy | | | | false
You can see how the first Envoy sidecar is not getting updates for its cluster instances for the svc-b upstream.
Looking at its stats:
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.update_attempt: 29
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.update_empty: 0
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.update_failure: 8
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.update_no_rebuild: 0
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.update_rejected: 0
cluster.svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul.update_success: 16
# ...
listener_manager.lds.init_fetch_timeout: 0
listener_manager.lds.update_attempt: 12
listener_manager.lds.update_failure: 8
listener_manager.lds.update_rejected: 0
listener_manager.lds.update_success: 3
listener_manager.lds.update_time: 1625348489181
listener_manager.lds.version: 17241709254077376921
listener_manager.lds.version_text: ""
8 failures. Other sidecars have the same LDS/CDS config versions, but with correct cluster instance IPs, and no failures in updating.
Failed Requests
We noticed this in errors:
[2021-07-03 12:24:42.078][1][warning][config] [source/common/config/grpc_subscription_impl.cc:119] gRPC config: initial fetch timed out for type.googleapis.com/envoy.config.endpoint.v3.ClusterLoadAssignment
[2021-07-03 21:40:39.863][1][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:101] DeltaAggregatedResources gRPC config stream closed: 13,
[2021-07-03 21:40:40.206][1][warning][config] [bazel-out/k8-opt/bin/source/common/config/_virtual_includes/grpc_stream_lib/common/config/grpc_stream.h:101] DeltaAggregatedResources gRPC config stream closed: 14, upstream connect error or disconnect/reset before headers. reset reason: connection termination
We also noticed this, but it seems to be related to hashicorp/nomad#10846
Jul 6 16:40:13 nomad-client-xxxx consul [13260]: 2021-07-06T16:40:13.066Z [ERROR] agent.envoy: Error receiving new DeltaDiscoveryRequest; closing request channel: error="rpc error: code = Canceled desc = context canceled"
Envoy Debugging
Turning on debug logging for Envoy shows this:
[2021-07-06 18:20:36.678][15][debug][upstream] [source/common/upstream/cluster_manager_impl.cc:1222] membership update for TLS cluster svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul added 0 removed 0
[2021-07-06 18:20:36.678][19][debug][upstream] [source/common/upstream/cluster_manager_impl.cc:1222] membership update for TLS cluster svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul added 0 removed 0
[2021-07-06 18:20:36.678][16][debug][upstream] [source/common/upstream/cluster_manager_impl.cc:1222] membership update for TLS cluster svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul added 0 removed 0
So that Envoy is getting updates, but they're stale.
Result: Outlier Detection Trips
Requests to stale clusters trip Envoy's outlier detection (expectedly so), and throw upstream connect error or disconnect/reset before headers. reset reason: connection failure errors:
[2021-07-06 18:22:39.680][16][debug][http] [source/common/http/conn_manager_impl.cc:261] [C35337] new stream
[2021-07-06 18:22:39.680][16][debug][http] [source/common/http/conn_manager_impl.cc:882] [C35337][S16870535376721757378] request headers complete (end_stream=true):
':authority', '0.0.0.0:8100'
':path', '/'
':method', 'POST'
'user-agent', 'curl/7.64.0'
'accept', '*/*'
'content-type', 'application/grpc'
[2021-07-06 18:22:39.680][16][debug][http] [source/common/http/filter_manager.cc:779] [C35337][S16870535376721757378] request end stream
[2021-07-06 18:22:39.680][16][debug][router] [source/common/router/router.cc:445] [C35337][S16870535376721757378] cluster 'svc-b.default.stg.internal.f73c09a4-ccb5-28bc-dc9e-1b5beff4b219.consul' match for URL '/'
[2021-07-06 18:22:39.680][16][debug][router] [source/common/router/router.cc:631] [C35337][S16870535376721757378] router decoding headers:
':authority', '0.0.0.0:8100'
':path', '/'
':method', 'POST'
':scheme', 'http'
'user-agent', 'curl/7.64.0'
'accept', '*/*'
'content-type', 'application/grpc'
'x-forwarded-proto', 'http'
'x-request-id', 'abcd1234'
[2021-07-06 18:22:39.680][16][debug][pool] [source/common/http/conn_pool_base.cc:74] queueing stream due to no available connections
[2021-07-06 18:22:39.680][16][debug][pool] [source/common/conn_pool/conn_pool_base.cc:241] trying to create new connection
[2021-07-06 18:22:39.680][16][debug][pool] [source/common/conn_pool/conn_pool_base.cc:143] creating a new connection
[2021-07-06 18:22:39.680][16][debug][client] [source/common/http/codec_client.cc:43] [C35338] connecting
[2021-07-06 18:22:39.680][16][debug][connection] [source/common/network/connection_impl.cc:860] [C35338] connecting to xx.xx.xx.88:21936
[2021-07-06 18:22:39.680][16][debug][connection] [source/common/network/connection_impl.cc:876] [C35338] connection in progress
[2021-07-06 18:22:39.680][16][debug][http2] [source/common/http/http2/codec_impl.cc:1222] [C35338] updating connection-level initial window size to 268435456
[2021-07-06 18:22:39.680][16][debug][connection] [source/common/network/connection_impl.cc:674] [C35338] delayed connection error: 111
[2021-07-06 18:22:39.680][16][debug][connection] [source/common/network/connection_impl.cc:243] [C35338] closing socket: 0
[2021-07-06 18:22:39.681][16][debug][client] [source/common/http/codec_client.cc:101] [C35338] disconnect. resetting 0 pending requests
[2021-07-06 18:22:39.681][16][debug][pool] [source/common/conn_pool/conn_pool_base.cc:393] [C35338] client disconnected, failure reason:
[2021-07-06 18:22:39.681][16][debug][router] [source/common/router/router.cc:1091] [C35337][S16870535376721757378] upstream reset: reset reason: connection failure, transport failure reason:
[2021-07-06 18:22:39.681][16][debug][http] [source/common/http/filter_manager.cc:883] [C35337][S16870535376721757378] Sending local reply with details upstream_reset_before_response_started{connection failure}
[2021-07-06 18:22:39.681][16][debug][http] [source/common/http/conn_manager_impl.cc:1469] [C35337][S16870535376721757378] encoding headers via codec (end_stream=true):
':status', '200'
'content-type', 'application/grpc'
'grpc-status', '14'
'grpc-message', 'upstream connect error or disconnect/reset before headers. reset reason: connection failure'
'date', 'Tue, 06 Jul 2021 18:22:39 GMT'
'server', 'envoy'
[2021-07-06 18:22:39.681][16][debug][connection] [source/common/network/connection_impl.cc:633] [C35337] remote close
[2021-07-06 18:22:39.681][16][debug][connection] [source/common/network/connection_impl.cc:243] [C35337] closing socket: 0
[2021-07-06 18:22:39.681][16][debug][conn_handler] [source/server/active_tcp_listener.cc:76] [C35337] adding to cleanup list
As described above, you can see it attempting to connect to the no-longer-existent sidecar on port 21936, instead of the correct one at 23637.