Ideas and Tips for using Github Features in Fisheries Projects
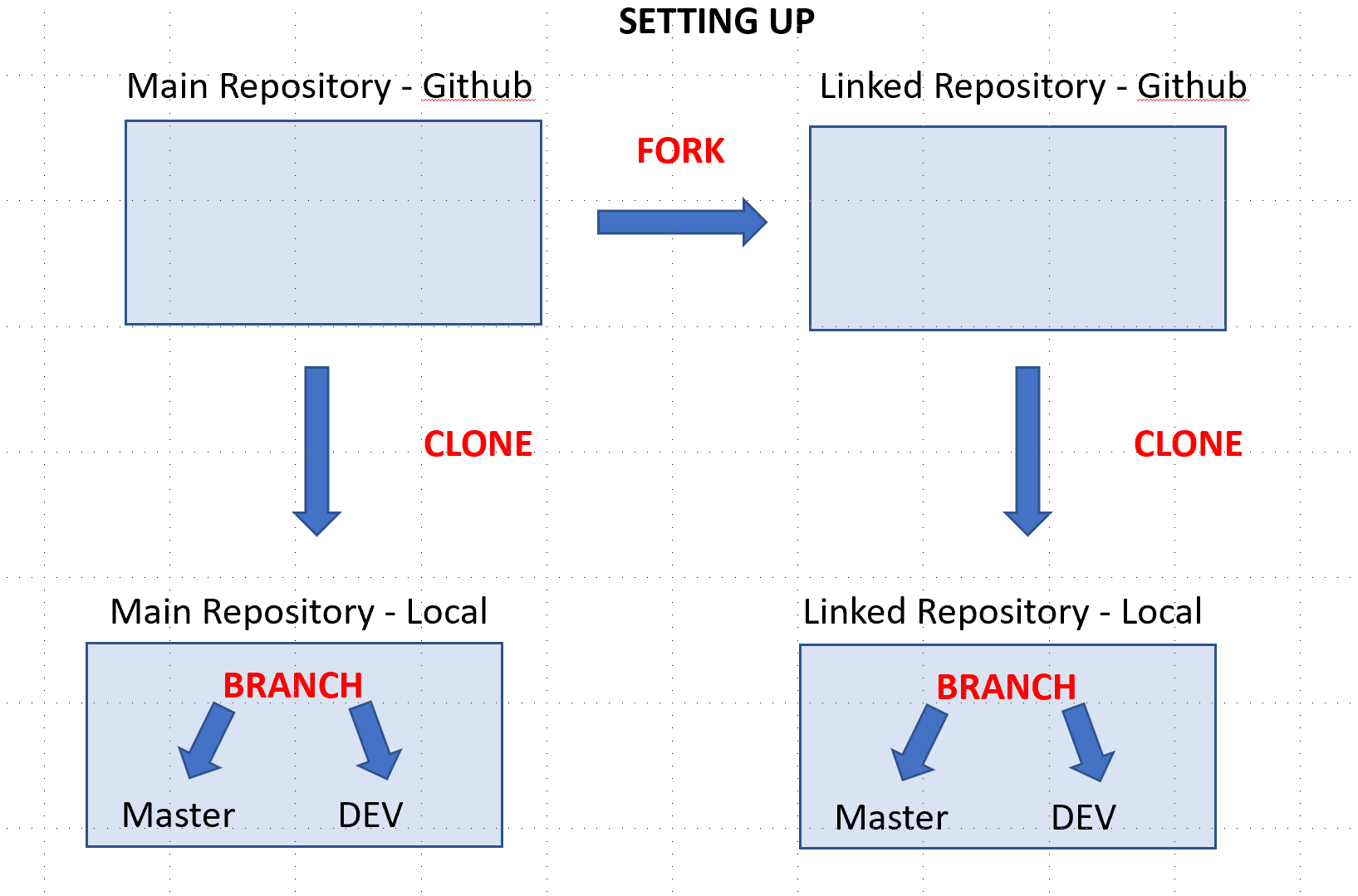
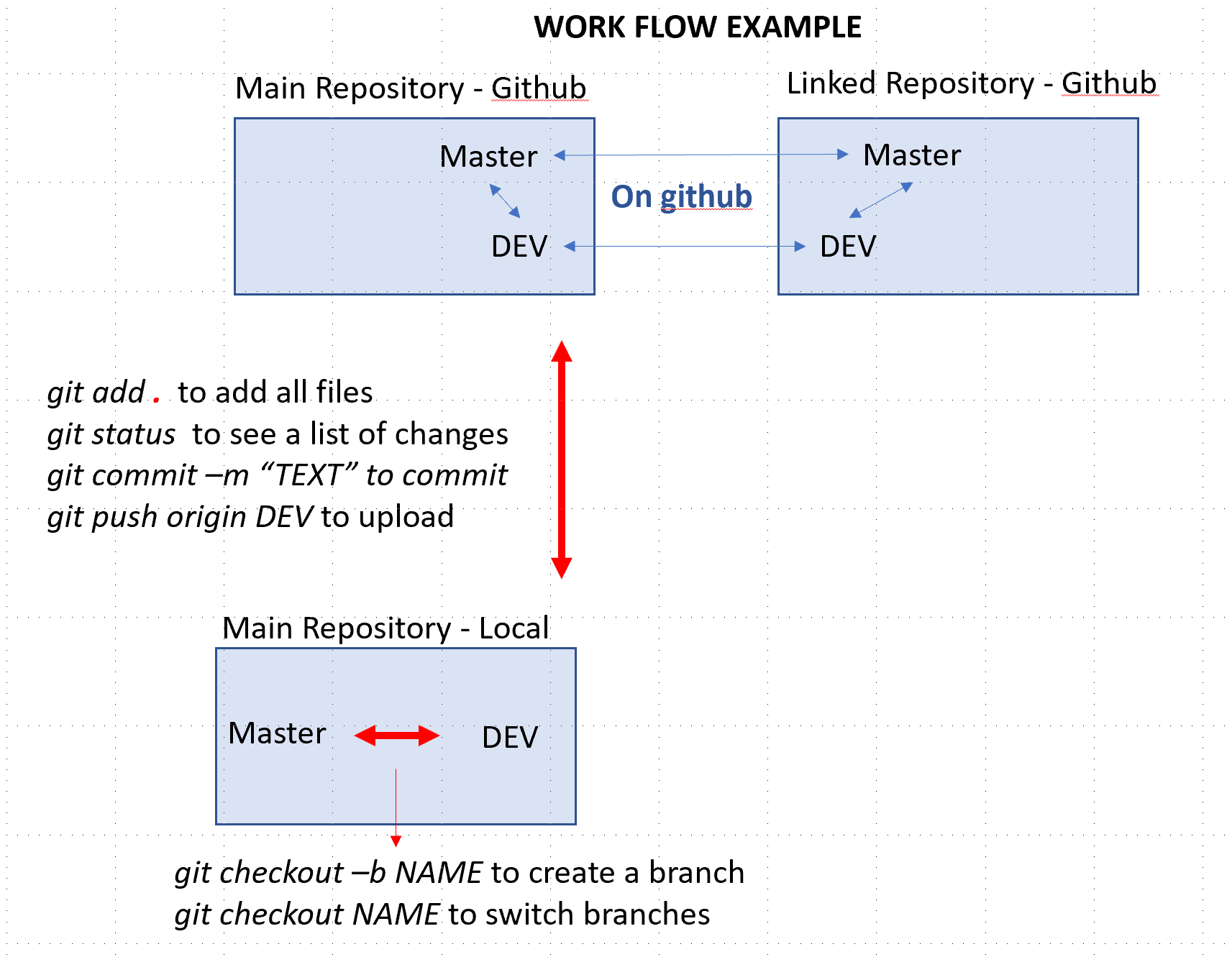
Github has 3 features that help with documenting your work, coordinating among contributors, and communicating with people who use the resulting data/code/outputs:
- issue threads
- readme files
- wiki pages
With a bit of creative adaptation, you can use a combination of these 3 features to do a whole lot of stuff. Below are some suggestions.
The basic idea of the issue threads is to open 1 issue for each bug/task, then discuss it with others, and close it when it's done (like this). However, you can also use it as a bulletin board (e.g. to collaboratively develop a meeting agenda and then include a short summary of the meeting, like this).
Issue threads are searchable, and that becomes really useful for longer projects (e.g. "What did we decide about en-route mortality assumptions last year?")
Within any folder, github will look for a file README.md and display it like website. In the readme files you can use all the features of basic markdown, like formatting, lists, task lists, and links.
Readme files are really useful to orient others in the repository and document the different pieces. For example, describe the purpose of a specific analysis in a subfolder, like here, or describe data sources like here and here.
Wiki pages are a good place write up background information about the project and methods. Think of these like a manual that goes with the code, and a preliminary version of the methods section for the report. For example, see here.
Each project will have its own unique requirements and dynamics that shape how the repository evolves. Here is a suggested starting point:
- DATA folder for all data files, with sub folders for raw inputs (BaseData), processed data (where you put the cleaned and reorganized records you are actually using for the analyses), and tracking files (e.g. where you put record mismatches, diagnostic summaries on missing records, etc.)
- FUNCTIONS folder for stand-alone functions that get used repeatedly in the analysis (e.g. Rec2Run(), plotTradeOff())
- SCRIPTS folder for the R code that runs the actual analyses. Consider numbering the script file names (e.g. 1_Read&Process_Data.R, 2_ExploratoryPlots.R). Also, if there are distinct components of the analysis, put the scripts into different folders (e.g. InseasonEstimates, GSIEstimates)
- OUTPUT folder where figures, csv files with simulation output etc are stored. These are usually not tracked (see gitignore below), but periodically zipped up and shared through a different platform (e.g. dropbox).
Follow the links above to see examples.
Not everything in your local directory should be tracked and shared via github. You can exclude specific files, file types, and folders by listing them in the .gitignore file (e.g. this one).
# ignore certain file types
*.pdf
*.doc
*.docx
# ignore some folders/subfolders
ProjectManagement
DATA/BaseData/LargeFiles
# The rest of these are from the default gitignore for R.
.Rhistory
.Rapp.history
.RData
include a brief description of how to combine github, markdown, bookdown, RStudio
then link to a wiki page for each