É notório que o controle de candidatos à doação de sangue é fundamental para garantir um estoque seguro e suficiente nos bancos de sangue. Atualmente, a coleta e análise desses dados são feitas de forma manual, dificultando a identificação rápida de doadores aptos e a organização das doações. Neste contexto, propõe-se o desenvolvimento do SysDoa, um sistema móvel que permite não só uma gestão virtual de candidatos de uma agência de banco de sangue, como também possibilita análises estatísticas das informações coletadas.
O escopo define os limites e objetivos do projeto, estabelecendo o que será ou não implementado. No SysDoa, ele orienta o desenvolvimento conforme as necessidades da clínica. Dessa forma, cada interação representa uma fase com evoluções específicas no sistema. Veja a seguir o escopo de cada interação:
Neste momento, o sistema SysDoa será desenvolvido exclusivamente para atender uma clínica específica. Por isso, algumas funcionalidades serão deliberadamente excluídas desta versão inicial, como:
- Cadastro individual de candidatos;
- Edição e exclusão de registros;
- Funcionalidades de login e registro de usuários.
Por outro lado, o sistema contará com:
- Cadastro de candidatos por lote via upload de arquivos jsons;
- Listagem de possíveis doadores de sangue;
- Informações estatísticas de quantos candidatos existem em cada estado do Brasil;
- Informações estatísticas do IMC médio em cada faixa de idade de dez em dez anos;
- Informações estatísticas do percentual de obesos entre os homens e entre as mulheres;
- Informações estatísticas da média de idade para cada tipo sanguíneo;
- Informações estatísticas da quantidade de possíveis doadores para cada tipo sanguíneo receptor.
O projeto segue uma estrutura clara de pastas para ajudar na manutenção e colaboração em equipe. Dessa forma, para nortear a organização dos artefatos de requisitos do produto, adotou-se a seguinte hierarquia de diretórios:
documentos
↳ requisitos
↳ funcionais
↳ nao-funcionais
Essa separação permite localizar rapidamente os arquivos e manter a rastreabilidade entre os tipos de requisito.
Para padronizar nomes, evitar confusões e facilitar buscas, foi adotado o seguinte padrão de nomeclatura dos artefatos:
-
Diretórios: em minúsculas, sem pontuações e separados por hífem em vez de espaços;
-
Requisitos: em Markdown (.md) e nomeados com letras maiúsculas para destaque, além de iniciar com o prefixo RF para requisitos funcionais e RNF para requisitos não funcionais, sempre fornecendo o número de identificação posteriormente.
Para garantir rastreabilidade e facilitar a validação dos requisitos ao longo do projeto, será adotado um modelo padronizado. Veja a seguir as regras de padronização dos requistos funcionais e não funcionais:
-
Requisitos funcionais incluirão campos como caso de uso, fluxos, atores e tabelas de dados, permitindo compreender claramente o comportamento esperado do sistema. Dessa forma, o modelo definido deve conter os campos conforme a ordem seguinte:
- Identificador: código único que permite identificar o requisito de forma rastreável;
- Caso de Uso: nome objetivo da funcionalidade que representa o comportamento esperado do sistema;
- Descrição: explica de forma clara o que o sistema deve fazer e qual o objetivo da funcionalidade, geralmente com o foco no usuário final e no propósito do requisito;
- Impacto: grau de importância da característica funcional para o sistema, normalmente definidas como Alta, Média e Baixa;
- Atores: papeis de usuários ou sistemas externos que interagem com a funcionalidade;
- Pré-condições: condições que precisam ser verdadeiras ou existentes antes do início da execução da funcionalidade.
- Pós-condições: Estado esperado do sistema após a execução bem-sucedida da funcionalidade;
- Fluxos Principais: sequência de passos padrão (cenário de sucesso) que o usuário e o sistema seguem para realizar a funcionalidade;
- Fluxos Alternativos: Caminhos alternativos que o usuário pode seguir, mas que ainda resultam no sucesso da operação;
- Fluxos de Exceções: Situações de erro ou imprevistos que podem ocorrer durante o fluxo, com as respectivas ações do sistema;
- Dependências: outros requisitos que precisam estar presentes ou operacionais para que este requisito funcione corretamente.
- Cardinalidades: Quantidade mínima e máxima de interações entre entidades envolvidas. Pode ser omitido se não houver impacto no requisito;
- Tabelas de Dados: Define os dados usados ou manipulados pela funcionalidade Cada campo da tabela contém:
- Nome: nome da informação;
- Tipo: tipo de dado;
- Valor Obrigatório: se o campo é ou não obrigatório ser preenchido;
- Restrições: validações ou limitações;
- Observações Extras: informações adicionais relevantes que não se enquadram nos campos anteriores.
-
Requisitos não funcionais terão estrutura simples com identificador, prioridade e categoria, focando em restrições e qualidades do sistema. Dessa forma, o modelo definido deve conter os campos conforme a ordem seguinte:
- Identificador: código único que permite identificar o requisito de forma rastreável;
- Descrição: explica a qualidade, restrição ou condição que o sistema deve cumprir, sem estar diretamente relacionado a uma funcionalidade específica.
- Impacto: grau de importância da característica não funcional para o sistema, normalmente definidas como Alta, Média e Baixa;
- Categoria: classificação do requisito não funcional com base em seu foco, como:
- Segurança: proteção de dados sensíveis;
- Capacidade: armazenamento e processamento necessários;
- Compatibilidade: suporte a sistemas e hardware;
- Disponibilidade: estabilidade e tempo online;
- Manutenibilidade: facilidade de suporte técnico;
- Escalabilidade: crescimento sem perda de desempenho;
- Usabilidade: facilidade e experiência do usuário;
- Desempenho: tempo de resposta adequado;
- Conformidade: atendimento a normas legais;
- Ambiental: adaptação ao ambiente físico.
- Observações Extras: informações adicionais relevantes que não se enquadram nos campos anteriores.
O processo de desenvolvimento de artefatos de requisitos estabelece as fases em que os requisitos do sistema são criados, revisados e atualizados ao longo do projeto. Essa definição garante a rastreabilidade e alinhamento contínuo entre as necessidades do sistema e sua implementação. Veja na tabela baixo mais detalhes de cada fase aplicada.
| Fase | Descrição | Momento | Resultados | Rastreabilidade |
|---|---|---|---|---|
| Criação | Documentação inicial dos requisitos do sistema com base no levantamento com stakeholders | Início de cada interação do projeto | requisitos funcionais e não funcionais criados com padrão definido | Sempre referenciando o commit com o prefixo feat e a identificação do requisito. Exemplos: "feat (RFxxx): ...", "feat (RNFxxx): ..." |
| Revisão | Correção de erros ou ambiguidades nos requisitos existentes | Após testes, validações ou feedbacks internos | Ajustes nos textos ou regras dos requisitos | Sempre referenciando o commit com o prefixo fix e a identificação do requisito. Exemplos: "fix (RFxxx): ...", "fix (RNFxxx): ..." |
| Atualização | Modificações nos requisitos para refletir novas funcionalidades, melhorias ou mudanças externas | A cada nova demanda ou mudança de escopo | Versões novas dos requisitos funcionais ou não funcionais | Sempre referenciando o commit com o prefixo refactor e a identificação do requisito. Exemplos: "refactor (RFxxx): ...", "refactor (RNFxxx): ..." |
O projeto tenta seguir diretrizes do Processo Unificado Racional (RUP – Rational Unified Process), adotando um ciclo de vida interativo e incremental.
O RUP é dividido em quatro fases: concepção, elaboração, construção e transição. Conheça abaixo detalhes de cada fase do modelo de processo adotado neste projeto.
A fase de concepção é estabelecer um business case para o sistema. Você deve identificar todas as entidades externas (pessoas e sistemas) que vão interagir com o sistema e definir as interações. Então, você deve usar essas informações para avaliar a contribuição do sistema para o negócio. Se essa contribuição for pequena, então o projeto poderá ser cancelado depois dessa fase. Sommerville (2011, p. 34)
As metas da fase de elaboração são desenvolver uma compreensão do problema dominante, estabelecer um framework da arquitetura para o sistema, desenvolver o plano do projeto e identificar os maiores riscos do projeto. No fim dessa fase, você deve ter um modelo de requisitos para o sistema, que pode ser um conjunto de casos de uso da UML, uma descrição da arquitetura ou um plano de desenvolvimento do software. Sommerville (2011, p. 34)
A fase de construção envolve projeto, programação e testes do sistema. Durante essa fase, as partes do sistema são desenvolvidas em paralelo e integradas. Na conclusão dessa fase, você deve ter um sistema de software já funcionando, bem como a documentação associada pronta para ser entregue aos usuários. Sommerville (2011, p. 34)
A fase final do RUP implica transferência do sistema da comunidade de desenvolvimento para a comunidade de usuários e em seu funcionamento em um ambiente real. Isso é ignorado na maioria dos modelos de processo de software, mas é, de fato, uma atividade cara e, às vezes, problemática. Na conclusão dessa fase, você deve ter um sistema de software documentado e funcionando corretamente em seu ambiente operacional. Sommerville (2011, p. 34)
A seguir, apresenta-se uma matriz que relaciona as fases do RUP com os principais artefatos de entrada e saída, ações executadas e os papéis responsáveis por cada etapa. Essa estrutura contribui para a rastreabilidade do processo de desenvolvimento de software, tornando mais claro quem faz o quê, quando e com base em quais artefatos.
| Fase | Artefato de Entrada | Ação | Artefato de Saída | Papel Responsável |
|---|---|---|---|---|
| Concepção | Contexto | Definir | Escopo | Product Owner |
| Concepção | Escopo | Especificar | Documento de Requisitos (PRD) | Development Team |
| Elaboração | PRD | Escrever | Histórias de Usuário | Product Owner |
| Elaboração | Histórias de Usuário | Planejar | Backlog do Produto | Scrum Master |
| Construção | Backlog do Produto | Desenvolver | Produto Incrementado | Development Team |
| Construção | Produto Incrementado | Testar | Produto Ajustado | Development Team |
| Transição | Produto Ajustado | Implantar | Produto Finalizado | Development Team |
| Transição | Produto Finalizado | Avaliar | Documento de Feedback | Product Owner |
As atividades representam as tarefas realizadas durante o desenvolvimento do sistema, como correções, melhorias ou novas funcionalidades. Neste contexto, a classificação das atividades permite controlar e rastrear as mudanças feitas no código, relacionando cada uma aos requisitos do projeto. Dessa forma, a categorização evolutiva em conjunto com a padronização de issues e rastreabilidade commits, torna possível a garantia entre o que foi planejado e o que foi implementado, promovendo qualidade e transparência no processo.
Cada atividade do projeto é classificada conforme sua natureza, o que ajuda a identificar o tipo de evolução do sistema e manter a rastreabilidade com os requisitos. Os tipos são:
| Tipo de Evolução | Descrição | Momento | Prefixo do Commit | Rastreabilidade |
|---|---|---|---|---|
| Evolutiva | Adiciona funcionalidades novas ou melhorias planejadas | Quando a funcionalidade já estava prevista na interação | feat | Sempre referenciando o commit com o prefixo feat e a identificação da issue. Exemplo: "feat Frontend #01: ..." |
| Corretiva | Corrige erros, falhas de lógica ou validações que impedem o funcionamento adequado | Quando é necessário consertar algo que foi implementado incorretamente ou contém bug | fix | Sempre referenciando o commit com o prefixo fix e a identificação da issue. Exemplo: "fix Backend #02: ..." |
| Adaptativa | Altera o sistema para se adaptar a mudanças externas | Quando há necessidade de ajustes técnicos que não alteram a lógica funcional | refactor | Sempre referenciando o commit com o prefixo refactor e a identificação da issue. Exemplo: "refactor Frontend #03: ..." |
As issues são usadas para planejar, distribuir e acompanhar as atividades do projeto. Elas estão localizadas no Project (projeto) desta organização e cada uma deve conter informações completas para garantir entendimento e rastreabilidade. Neste contexto, o modelo adotado de issue/atividade segue o consecutivo padrão abaixo:
- Identificador: número de identificação de cada issue. É gerado automaticamente;
- Título: curto, descrevendo o que deve ser feito e referenciando o repositório para a sua construção;
- Descrição: estruturada com:
- História de Usuário: uma história de usuário, no formato Como [papel] Quero [ação], Para [finalidade].
- Requisitos Associados: associação de requisitos na atividade, que podem ser Requisitos Funcionais (RF) e Requisitos Não Funcioanis (RNF);
- Complemento: campo opcional com informações extras para orientar o realizador da tarefa.
- Prioridade (Priority): nível de urgência classificadas em:
- P0: crítica e bloqueia outras funcionalidades;
- P1: importante, mas não bloqueia outras funcionalidades;
- P2: pode ser feita depois, sem impacto imediato.
- Construção (Construction): tipo de evolução de artefato, podendo ser:
- Evolutiva (Evolutionary): adiciona funcionalidades novas ou melhorias planejadas;
- Corretiva (Corrective): corrige erros, falhas de lógica ou validações que impedem o funcionamento adequado;
- Adaptativa (Adaptive): altera o sistema para se adaptar a mudanças externas.
- Estimativa (Estimate): tempo estimado para a execução (em dias).
- Tamanho (Size): complexidade da tarefa:
- XS: ajuste simples (ex: correção de texto);
- S: alteração pequena (ex: adicionar campo);
- M: funcionalidade moderada (ex: novo formulário);
- L: alteração abrangente (ex: lógica com múltiplos arquivos);
- XL: atividade complexa ou com pesquisa/investigação.
- Data de Início (Start Date) e Data de Fim (End Date): para controle de tempo real de execução.
- Interação (Iteration): a qual sprint/interação a tarefa pertence (deve durar entre 15 a 30 dias).
- Responsável (Assignees): membro(s) atribuídos para executar a tarefa;
- Repositório (Repository): repositório associado a issue.
Para assegurar que toda atividade esteja corretamente vinculada aos requisitos e devidamente classificada conforme a natureza da evolução, adotamos os seguintes mecanismos:
- Uso obrigatório de issues no GitHub: nenhuma alteração no código é feita sem uma issue correspondente, a qual deve referenciar claramente os requisitos envolvidos (RF e/ou RNF);
- Commits padronizados: todos os commits seguem o padrão de prefixo (feat, fix, refactor) e referenciam o número da issue;
- Checklist de Pull Requests: Toda PR (pull request) deve conter:
- Link para a issue correspondente;
- Descrição do requisito atendido;
- Tipo de evolução realizada;
- Revisão de código obrigatória: antes da aprovação de qualquer PR, um membro do grupo verifica se a atividade está relacionada a um requisito documentado e classificada corretamente.
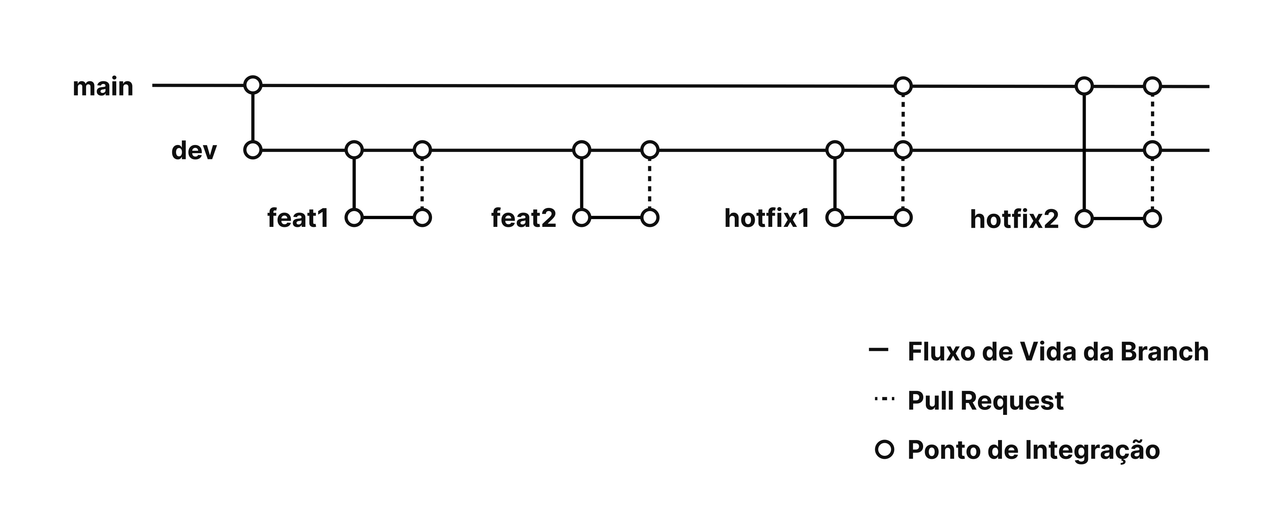
O controle de mudanças é um processo estruturado para gerenciar modificações no código-fonte de um projeto, garantindo estabilidade, rastreabilidade e qualidade. Ele define como as alterações são desenvolvidas, testadas e promovidas até a produção, minimizando riscos e falhas. Dessa forma, utilizamos Git como sistema de controle de versão distribuído e GitHub como plataforma para gerenciamento de repositórios, revisão de código e colaboração entre desenvolvedores.
-
Branches das issues:
- Linhas responsáveis pelo de desenvolvimento, criada a partir da branch "dev";
- A branch deve começar com o prefixo "feat/", depois o nome da funcionalidade que será tratada. Exemplo: feat/cadasto-lote-candidato;
- As issues são criadas a partir da main, caso seja a primeira a ser criada, ou a partir de outra branch já testada, caso possua outras branches que podem ser aproveitadas;
- Cada issue terá sua própria branch para desenvolvimento;
- Após a implementação, deve-se abrir um Pull Request para a branch "dev";
-
Homologação:
- Linha responsável por validar as branches criadas antes de ser envida para a produção;
- Linha criada a partir da branch "main";
- Caso todas as branches criadas sejam validadas com sucesso nesta linha, haverá um Pull Request para a linha de produção, ou seja, para a branch "main";
- Caso exista algum erro ao realizar a validação de alguma branch enviada para essa linha, serão criadas branches de correção até que tudo esteja validado com sucesso.
-
Produção:
- Linha responsável por receber códigos validados pela branch de homologação e por subir o sistema para o servidor de produção automaticamente;
- Se trata da linha chamada "main";
- Caso exista algum erro no sistema em produção, será feita a restauração do "commit" anterior, caso exista versões antigas, e serão criadas branches de correção.
-
Branches das hotfix/correções de erro:
- Linha responsável pela correção de erros verificada na branch de homologação ou produção;
- A branch deve começar com o prefixo "hotfix/", depois o nome da funcionalidade que será tratada. Exemplo: hotfix/validacao-imc-candidato;
- Se um erro for identificado nas validações da linha "dev" ou na "main", uma nova branch de hotfix será criada a partir dela;
- Cada correção será implementada, testada e, se aprovada, integrada novamente à dev, assim como nas branches de issues.
O fluxo ilustrado abaixo demonstrando as linhas de desenvolvimento (branches das issues, representadas por "feat"), homologação ("dev"), produção ("main") e correções ("hotfix"). Esse diagrama reforça a importância de seguir o processo para garantir a qualidade e integridade do código.