| title | LLM Safety guardian | |||||
|---|---|---|---|---|---|---|
| emoji | 😢 | |||||
| colorFrom | red | |||||
| colorTo | green | |||||
| sdk | docker | |||||
| app_port | 7860 | |||||
| pinned | true | |||||
| short_description | High-risk message detector for LLM safety. | |||||
| tags |
|
LLMs are increasingly used in high-risk scenarios — including medical, legal, and psychological consultations — where model errors can have serious consequences. Recent legal cases highlight the need for external monitoring mechanisms capable of identifying high-risk user inputs and mitigating potential harm for both users and developers.
This project provides an independent safety layer that evaluates user–assistant dialogs and detects messages that may require the model to stop, redirect, or escalate the interaction according to safety guidelines.
The classifier acts as an external observer, scoring each message for potential risk and recommending whether the LLM should continue the conversation or trigger a safety response. This reduces the risk of harmful interactions, helps companies comply with Responsible AI standards, and prevents situations that may result in legal or reputational damage.
git clone https://github.com/Tamplier/llm_safety_guardian.git
cd llm_safety_guardian
# prepare input (fix typos, generate extra features, vectorize text)
invoke prepare-input
# retrain models
invoke retrain-model
# Build and run Docker container
docker build -t llm_safety_guardian .
# command line interface
docker run -it llm_safety_guardian invoke cli
# run telegram bot
docker run -e TELEGRAM_TOKEN="YOUR_TOKEN_HERE" llm_safety_guardian invoke start-telegram-bot
This project contains a machine learning model trained on a dataset containing examples of crisis communication. The dataset is balanced, which allowed us to use simple accuracy as the primary evaluation metric.
Before training, a preliminary exploratory analysis was conducted.
The dataset consists of natural text, which includes typos, elongated words like "soooooo sory", emoticons, self-censorship such as "you s!ck", and word concatenations like "STOP|STOP|STOP". To handle this, a preprocessing step was applied to clean the text ( here and here ).
In addition, several features were engineered, including the percentage of uppercase letters, ratio of exclamation and question marks to the number of sentences, presence and count of self-censorship, text length, number of sentences, and number of individual emoticons. After evaluating multiple approaches, the most informative features were selected and integrated into the dataset.
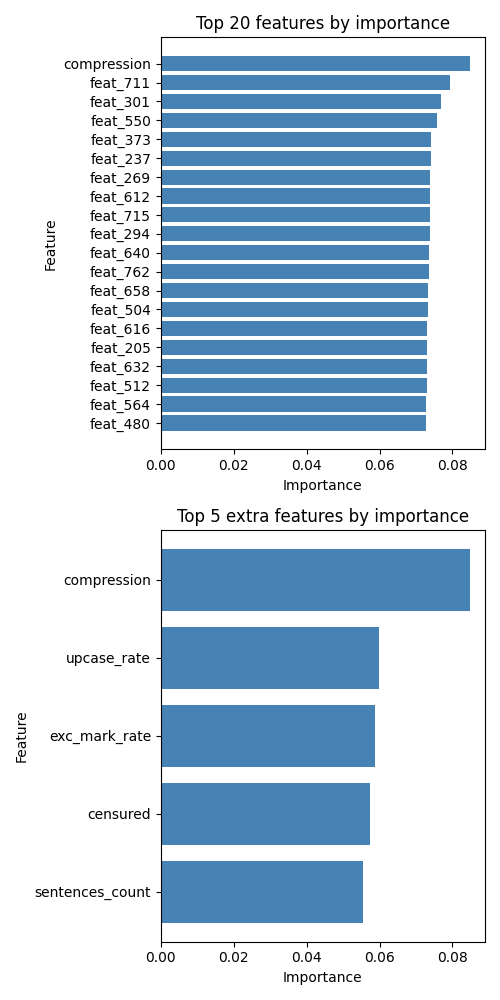
As shown in the plot below, the two most important features for the classification task originate from the custom feature extractor:
- Question mark rate
- Compression — a metric indicating how much a text is reduced due to repeated characters (e.g., “!!!!” or “sooooo”)
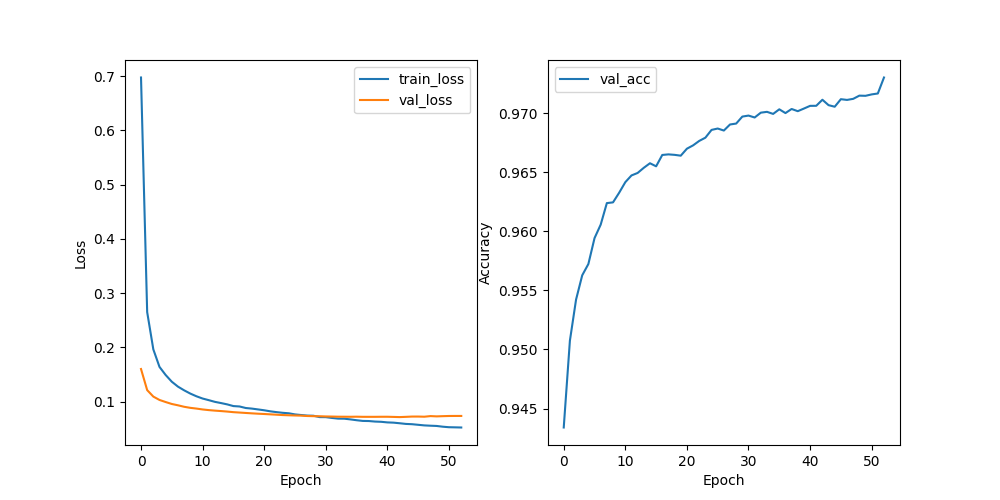
Training was performed on a GPU in Kaggle. SBERT sentence transformer was used to vectorize preprocessed text and ANN (Torch) to create a classifier based on vectors and extra features from previous step.
Hyperparameter optimization was performed using Optuna and 3 fold cross validation. The final model achieved approximately 95% accuracy on the validation data. More detailed results (available in the training log) are as follows:
- Accuracy: 95.54% [95.38%, 95.70%]
- Precision: 95.29% [95.07%, 95.51%] (about 95% of the records labeled as positive are actually positive)
- Recall: 95.82% [95.61%, 96.03%] (about 95% of postitive records were found) The given 95% confidence intervals were obtained using bootstrap resampling with n = 10,000.
Confusion matrix:
| Predicted Safe message | Predicted High-risk message | |
|---|---|---|
| True Safe message | 33,162 | 1,650 |
| True High-risk message | 1,455 | 33,356 |
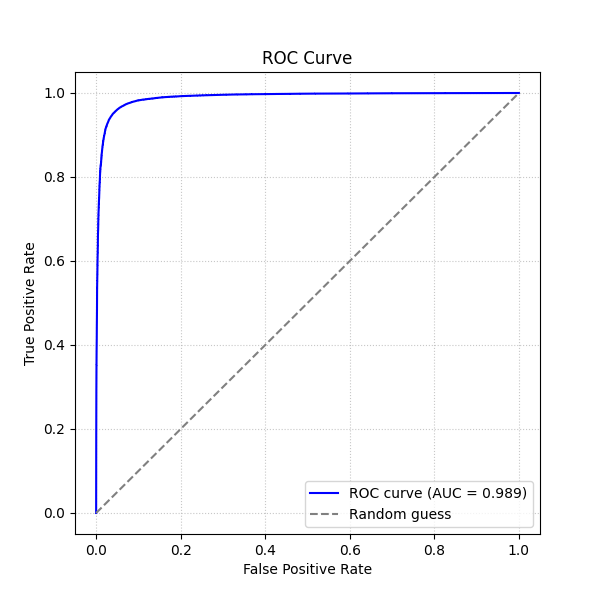
The ROC curve shows that the data are well separated. The true positive rate increases to about 80% with almost no increase in the false positive rate.
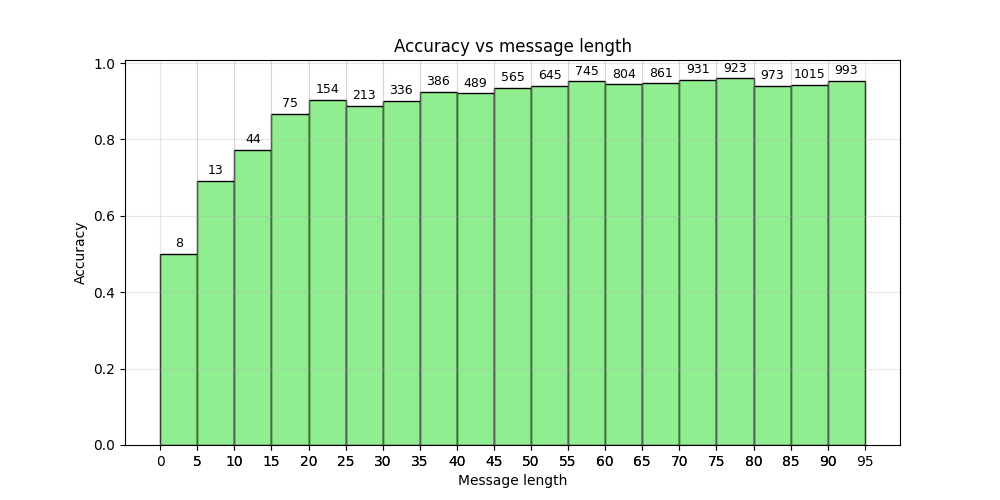
The last graph shows an intuitive relationship: the shorter the message, the less accurate the classification. The graph shows that with a message less than 5 characters long, classification is like we're flipping a coin, and acceptable accuracy is achieved only for messages longer than 15 characters. Of course, there are not many messages in the ranges up to 5 (there are only 8 messages in the test set) and up to 10 characters (13 messages only) to speak about accuracy with sufficient confidence, however, the reduced classification quality is obvious.
A Docker container was built containing all necessary dependencies, and it is used for all subsequent steps. For quality assurance, pytest runs inside the Docker container on every commit to the main branch, covering the core functionality of the project. The unit tests are available in tests folder.
Deployment to Hugging Face is handled via GitHub Actions. The deployment is manually triggered and blocked if any tests fail, ensuring only verified versions are released.
![]()
![]()
The Docker image size is approximately 1.7 GB, and the average RAM usage under normal conditions is around 1.25 GB. Since this is an educational, non-commercial project, one of the key goals was to minimize hosting costs. However, due to the inclusion of large machine learning models and dependencies such as SciPy and Torch, the memory requirements increased significantly.
Given these constraints, finding a free or low-cost hosting option was challenging. As a result, Hugging Face Spaces was chosen as the production environment. The project is currently deployed on this platform and can be accessed here: https://huggingface.co/spaces/Tapocheck77/llm_safety_guardian