A convolutional neural network to classify 5 different types of flowers. Avoidance of overfitting through data augmentation and dropout.
Classifying images can be a tough task, even more if there are lots of images to classify. It is obvious that at the beggining we will have to do it manually. Eventhough, since it is a repetitive task, we could train a neural network to do the job for us, using all the data that we classified manually.
In these types of tasks, the usual thing is to analyze all the patterns and design an algorithm. To analyze images, figuring out all the hidden patterns would be such a painfull work; instead of that, a neural network can handle the job. The type of neural network that we will use will be a convolutional one. The reason why is that it is equipped with tools that make the analysis of spacial patterns in images, such as contrast lines, hue gradients and so on.
The goal of the model will be to take an image of a flower and output a probability distribution corresponding to each type of flower it "thinks" it is.
EXAMPLE HERE
Tip
I recommend executing this Jupyter notebook in a google colab environment, using a GPU T4.
The modules that we will use are the usuals:
import os # system management
import numpy as np # arrays
import glob # filenames
import shutil # moving files
import matplotlib.pyplot as plt # plotting
import tensorflow as tf # neural networks
from tensorflow.keras.models import Sequential # sequential arquitecture
from tensorflow.keras.layers import Dense, Conv2D, Flatten, Dropout, MaxPooling2D # different layers
from tensorflow.keras.preprocessing.image import ImageDataGenerator # data generator from datasetThe dataset will be taken from the official TensorFlow examples. Using tf.keras.utils.get_file and extracting the .tgz file, we end up with a folder with all the already classified images.
_URL = "https://storage.googleapis.com/download.tensorflow.org/example_images/flower_photos.tgz"
zip_file = tf.keras.utils.get_file(origin=_URL,
fname="flower_photos.tgz",
extract=True)
base_dir = os.path.join(os.path.dirname(zip_file), 'flower_photos_extracted/flower_photos')Using the os module, we assign to base_dir the following path: /root/.keras/datasets/flower_photos_extracted/flower_photos. In future versions of the tf.keras module this could change; so, please, check where is your flower_photos directory.
/
└── root/
└── .keras/
└── datasets/
└── flower_photos_extracted/
└── flower_photos/
├── daisy
├── dandelion
├── roses
├── sunflowers
└── tulips
As it can be seen, we have 5 types of flowers: roses, daisy, dandelion, sunflowers and tulips.
classes = ['roses', 'daisy', 'dandelion', 'sunflowers', 'tulips']Now, using these classes, we have to create directories to separate the training data from the validation data. To do so, we use the os, blob and shutil modules; they allow us to move, create and select files/directories.
for cl in classes:
# search for the class directory
img_path = os.path.join(base_dir, cl)
# pick up the list of all .jpg images inside the dir
images = glob.glob(img_path + '/*.jpg')
# show how many are there
print("{}: {} Images".format(cl, len(images)))
# choose an 80% of the images to train
num_train = int(round(len(images)*0.8))
# classify them
train, val = images[:num_train], images[num_train:]
for t in train:
if not os.path.exists(os.path.join(base_dir, 'train', cl)):
# create "train/class" folder
os.makedirs(os.path.join(base_dir, 'train', cl))
# move all the images there
shutil.move(t, os.path.join(base_dir, 'train', cl))
# repeat for validation
for v in val:
if not os.path.exists(os.path.join(base_dir, 'val', cl)):
os.makedirs(os.path.join(base_dir, 'val', cl))
shutil.move(v, os.path.join(base_dir, 'val', cl))
# set up the paths
train_dir = os.path.join(base_dir, 'train')
val_dir = os.path.join(base_dir, 'val')roses: 641 Images
daisy: 633 Images
dandelion: 898 Images
sunflowers: 699 Images
tulips: 799 Images
Now, our training and validation datasets are contained in the paths pointed by train_dir and val_dir.
/
└── root/
└── .keras/
└── datasets/
└── flower_photos_extracted/
└── flower_photos/
├── daisy
├── dandelion
├── roses
├── sunflowers
├── tulips
├── train/
│ ├── daisy
│ ├── dandelion
│ ├── roses
│ ├── sunflowers
│ └── tulips
└── val/
├── daisy
├── dandelion
├── roses
├── sunflowers
└── tulips
To see an example of a simple model, we will train a neural network and will observe how it overfits. This is really common when beggining to work with neural networks. It is a phenomonon that is hard to avoid if you do not know where does it come from and how the network is designed internally.
The first thing to do is setting up an image data generator. This is a tensorflow.keras object that takes a directory (not loaded in the stack), processes images and makes batches out of it. This is a really useful tool to avoid your RAM overloading. Also, it has built-in tools that preprocess the image randomly, so the model can work out with an alternative version of the image to avoid overfitting (we will see this later).
The colors of the image (given by a [R,G,B] vector) will be normalized to 1 (that means, dividing them by 255). Finally, since simple neural networks can only work with a fixed image resolution, we will have to rescale them every time we try to feed them into the model (150x150 px).
The data generator will be set up to read from a directory (train_dir), using .flow_from_directory we can specify all the configurations (such as batch_size, order, target size, etc). A very important argument of this method is the class_mode='sparse'. This allows the data batch to include the final outputs depending on the directories where these images come from. Somehow, the directories where these images are contained work as a label, and they are set into the train_data_gen variable.
batch_size = 100
IMG_SHAPE = 150
image_gen = ImageDataGenerator(rescale=1./255)
train_data_gen = image_gen.flow_from_directory(
batch_size=batch_size,
directory=train_dir,
shuffle=True,
target_size=(IMG_SHAPE,IMG_SHAPE),
class_mode='sparse'
)Found 2935 images belonging to 5 classes.
Also, we can create an image data generator for the validation set:
image_gen_val = ImageDataGenerator(rescale=1./255)
val_data_gen = image_gen_val.flow_from_directory(batch_size=batch_size,
directory=val_dir,
target_size=(IMG_SHAPE, IMG_SHAPE),
class_mode='sparse')Found 735 images belonging to 5 classes.
As we said, we will be using a convolutional one. Basically it consists of some layers that operate (convolution) the image with some filters (the weight functions, mathematically) and output a new image. After each convolution we will apply a MaxPooling layer, which chooses the highest value out of the dimensions we indicate it. In our case, each MaxPooling layer will have dimensions 2x2, which means that the resulting image will have half the size (1/4 of the area).
We will apply the same combination 3 times, using 16, 32 and 64 filters respectively. Also, we will use the relu activation function, which allows us to capture the non-linear behaviour.
After that, We will flatten all the image components and apply dense layers until it reaches de desired size: 5 (for the 5 types of flowers).
model1 = Sequential()
model1.add(Conv2D(16, 3, padding='same', activation='relu', input_shape=(IMG_SHAPE,IMG_SHAPE, 3)))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(32, 3, padding='same', activation='relu'))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Conv2D(64, 3, padding='same', activation='relu'))
model1.add(MaxPooling2D(pool_size=(2, 2)))
model1.add(Flatten())
model1.add(Dense(512, activation='relu'))
model1.add(Dense(5))We can visualize how the model is built with the .summary() method.
model1.summary()Model: "sequential_1"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ conv2d_3 (Conv2D) │ (None, 150, 150, 16) │ 448 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_3 (MaxPooling2D) │ (None, 75, 75, 16) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_4 (Conv2D) │ (None, 75, 75, 32) │ 4,640 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_4 (MaxPooling2D) │ (None, 37, 37, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_5 (Conv2D) │ (None, 37, 37, 64) │ 18,496 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_5 (MaxPooling2D) │ (None, 18, 18, 64) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten_1 (Flatten) │ (None, 20736) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 512) │ 10,617,344 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_3 (Dense) │ (None, 5) │ 2,565 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 10,643,493 (40.60 MB)
Trainable params: 10,643,493 (40.60 MB)
Non-trainable params: 0 (0.00 B)
Now, we compile the model and set up how we want it to be trained. The optimizer will be the adam one (it is the most usual for simple neural networks. The loss function (which adam will try to minimize) will be the sparse categorical cross entropy . This one is basically a way to quantify how sure are we that we guessed the right type of flower.
model1.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])Finally, we train the model with 80 epochs (the times the network will look at our data) and track the validation with the validation set (val_data_gen) using the .fit method.
epochs = 80
history = model1.fit(
train_data_gen,
steps_per_epoch=int(np.ceil(train_data_gen.n / float(batch_size))),
epochs=epochs,
validation_data=val_data_gen,
validation_steps=int(np.ceil(val_data_gen.n / float(batch_size)))
)After approximately 11 minutes, we have our model trained. We can plot the accuracies and loss functions of the different trainig/validation sets:
# define the y values of the plots
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# define the x values
epochs_range = range(epochs)
# plot accuracy
plt.figure(figsize=(8, 8))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
# plot loss
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
As it can be seen, both accuracies begin to grow with the same rate at the beggining. When reaching 4 epochs, both curves get separated (the same happens with the loss function). The validation accuracy gets stuck at ~65%, while the training one grows up to ~100%.
This phenomenon is called overfitting. Basically, our model has learned the training set so perfectly that fails at predicting data outside of it. We now have the task to improve the model using overfitting avoidance techniques.
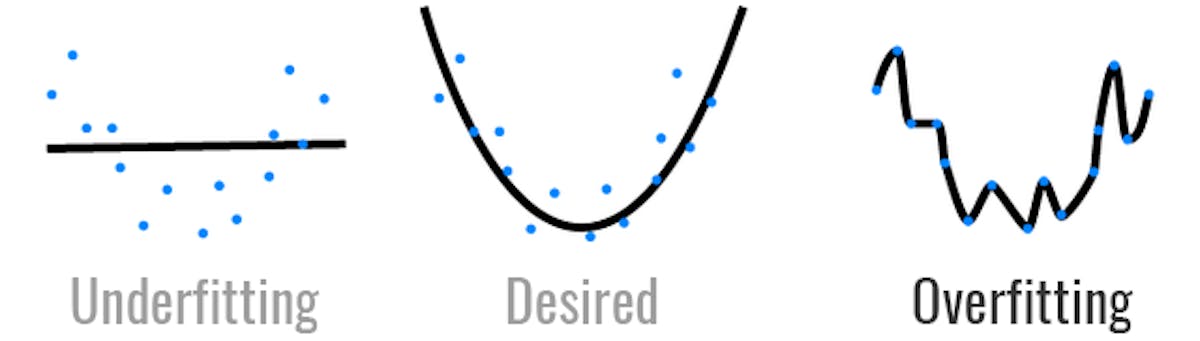
The problem of the first one was overfitting. There are different techniques to avoiod it, we will use data augmentation and dropout. We will explan them a little bit to get more context.
This tecnique consists basically on modifying a little bit the data that is used to train in each batch. This can be achieved easily using the image data generator. This time, we will call the function ImageDataGenerator with more arguments.
As before, we still use the rescaling (1/255), and add more features:
- Rotation range: rotates randomly the image between 0 and the angle we want (45º).
- Width/Height shift range: stretches the image dimensions randomly within a percentage (15%).
- Horizontal flip: Randomly, flips the image horizzontally.
- Zoom range: Makes a zoom to the image within a certain percentage (50%).
image_gen_train = ImageDataGenerator(
rescale=1./255,
rotation_range=45,
width_shift_range=.15,
height_shift_range=.15,
horizontal_flip=True,
zoom_range=0.5
)
train_data_gen = image_gen_train.flow_from_directory(
batch_size=batch_size,
directory=train_dir,
shuffle=True,
target_size=(IMG_SHAPE,IMG_SHAPE),
class_mode='sparse'
)Found 2935 images belonging to 5 classes.
We can now plot 5 different examples of how these transformations are applied randomply each time we call the train_data_gen variable (which is an ImageDataGenerator).
def plotImages(images_arr):
fig, axes = plt.subplots(1, 5, figsize=(20,20))
axes = axes.flatten()
for img, ax in zip(images_arr, axes):
ax.imshow(img)
plt.tight_layout()
plt.show()
augmented_images = [train_data_gen[0][0][0] for i in range(5)]
plotImages(augmented_images)
The validation set stays the same, since it is not used for training (it will not change the overfitting conditions).
This other technique consists on deactivating some of the neurons during the training. This is something that we implement inside the model while deciding its architecture. For our case, we will put dropout layers right at the end, before each dense layer.

model2 = Sequential()
model2.add(Conv2D(16, 3, padding='same', activation='relu', input_shape=(IMG_SHAPE,IMG_SHAPE, 3)))
model2.add(MaxPooling2D(pool_size=(2, 2)))
model2.add(Conv2D(32, 3, padding='same', activation='relu'))
model2.add(MaxPooling2D(pool_size=(2, 2)))
model2.add(Conv2D(64, 3, padding='same', activation='relu'))
model2.add(MaxPooling2D(pool_size=(2, 2)))
model2.add(Flatten())
model2.add(Dropout(0.2))
model2.add(Dense(512, activation='relu'))
model2.add(Dropout(0.2))
model2.add(Dense(5))
model2.summary()┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ conv2d_3 (Conv2D) │ (None, 150, 150, 16) │ 448 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_3 (MaxPooling2D) │ (None, 75, 75, 16) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_4 (Conv2D) │ (None, 75, 75, 32) │ 4,640 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_4 (MaxPooling2D) │ (None, 37, 37, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_5 (Conv2D) │ (None, 37, 37, 64) │ 18,496 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_5 (MaxPooling2D) │ (None, 18, 18, 64) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten_1 (Flatten) │ (None, 20736) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout (Dropout) │ (None, 20736) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_2 (Dense) │ (None, 512) │ 10,617,344 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_1 (Dropout) │ (None, 512) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_3 (Dense) │ (None, 5) │ 2,565 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 10,643,493 (40.60 MB)
Trainable params: 10,643,493 (40.60 MB)
Non-trainable params: 0 (0.00 B)
After all this, we recompile and train the new model.
model2.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])epochs = 80
history = model2.fit(
train_data_gen,
steps_per_epoch=int(np.ceil(train_data_gen.n / float(batch_size))),
epochs=epochs,
validation_data=val_data_gen,
validation_steps=int(np.ceil(val_data_gen.n / float(batch_size)))
)After 40 minutes, the model is completely trained. Again, we can plot the accuracies and loss functions:
# define the y values of the plots
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
# define the x values
epochs_range = range(epochs)
# plot accuracy
plt.figure(figsize=(12, 5))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='best')
plt.title('Training and Validation Accuracy')
# plot loss
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='best')
plt.title('Training and Validation Loss')
plt.show()
Is overfitting stil there? Of course, but this time it has gotten much better. This time we reached 81% of accuracy in the validation, which is a significant improve. This means that our model predicts correctly 4 out of 5 attempts, which is an impressive result for such a simple neural network.
Now that we have a functional model, we can save it into a .keras file that will contain all the information about it. The goal of this step is to have a start point whenever we want to continue using the model without having to train it again.
To do so, we use the .save method specifying the path where we want it to save.
import time
# use the timestamp to track the "version"
path = "./flowerclassifier_" + str(time.time()) + ".keras"
model2.save(path)We can also load it into another variable and use to test it with our own images.
model3 = tf.keras.models.load_model(path)
model3.summary()Model: "sequential"
┏━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━━━━━━━━━━┳━━━━━━━━━━━━━━━┓
┃ Layer (type) ┃ Output Shape ┃ Param # ┃
┡━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━━━━━━━━━━╇━━━━━━━━━━━━━━━┩
│ conv2d (Conv2D) │ (None, 150, 150, 16) │ 448 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d (MaxPooling2D) │ (None, 75, 75, 16) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_1 (Conv2D) │ (None, 75, 75, 32) │ 4,640 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_1 (MaxPooling2D) │ (None, 37, 37, 32) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ conv2d_2 (Conv2D) │ (None, 37, 37, 64) │ 18,496 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ max_pooling2d_2 (MaxPooling2D) │ (None, 18, 18, 64) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ flatten (Flatten) │ (None, 20736) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout (Dropout) │ (None, 20736) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense (Dense) │ (None, 512) │ 10,617,344 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dropout_1 (Dropout) │ (None, 512) │ 0 │
├─────────────────────────────────┼────────────────────────┼───────────────┤
│ dense_1 (Dense) │ (None, 5) │ 2,565 │
└─────────────────────────────────┴────────────────────────┴───────────────┘
Total params: 31,930,481 (121.81 MB)
Trainable params: 10,643,493 (40.60 MB)
Non-trainable params: 0 (0.00 B)
Optimizer params: 21,286,988 (81.20 MB)
As you can see, now, the optimizer information is also contained into the model. With this, we can continue training it from another starting point.
Now, we can try the neural network with some image. For example, this one:

To do so, we have to resize it to 150x150 px.
We can build a function that takes an image link and the expected prediction and returns a plot of the probability distribution, marking in green if the prediction is successful.
import requests
def Plotpred(prediction):
probability = tf.nn.softmax(prediction[0][0], axis=-1).numpy()
colorTrue = "#00AF3A"
colorFalse = "#AF0000"
colorOther = "#949494"
color = []
max = np.max(probability)
classes = ["daisy", "dandelion", "roses", "sunflowers", "tulips"]
pred = prediction[1]
for prob, typee in zip(probability, classes):
if typee == pred and prob == max:
color.append(colorTrue)
elif typee != pred and prob == max:
color.append(colorFalse)
else:
color.append(colorOther)
plt.bar(classes, probability, color=color)
plt.ylabel("Probability")
plt.title("Classification")
plt.show()
def Probplot(link, typee):
url = link
response = requests.get(url)
image_bytes = response.content
# decode image
img_tensor = tf.image.decode_image(image_bytes, channels=3)
img_tensor = tf.image.resize(img_tensor, [IMG_SHAPE, IMG_SHAPE])
img_tensor = tf.expand_dims(img_tensor, axis=0) # Add batch dimension
img_tensor = tf.cast(img_tensor, tf.float32) / 255.0
return Plotpred([model3.predict(img_tensor), typee])Probplot("https://www.gardenia.net/wp-content/uploads/2024/01/shutterstock_2084235901.jpg", "sunflowers")
As it can be seen, the prediction has been successful. Let's now try with a more difficult example. For example, this image:

Probplot("https://cdn.sanity.io/images/pn4rwssl/production/59c9dcc506862017ff8d7c237673bdafeba27487-500x750.jpg?w=2880&q=75&auto=format", "tulips")
This time, the classificator fails with high confidence. This is due to the fact that photos of roses are usually taken with the same image composition and similar colors.