
Machine Learning Engineer • Computer Vision • Multimodal Generative Models
Building intelligent systems for visual understanding, behavior generation, and real-time AI.

Multimodal generative model for generating realistic listener avatars in dyadic conversations, conditioned on personality traits. The model predicts facial expressions, head motion, and upper-body gestures of a listener from the speaker’s audio and motion signals.
![]()
-
Tech Stack: PyTorch · Vision-Transformers · VQ-VAE · SMPL-X (PIXIE)-Librosa · OpenCV · CUDA · TensorBoard SLURM · Enroot · Multi-GPU Training (A100)
-
Demo: Thesis Website
-
Paper: Full Thesis Document
End-to-end computer vision pipeline for badminton match analysis that converts badminton match videos into structured performance analytics for players and coaches. The system tracks both players and the shuttlecock, detects shot events, projects motion onto a mini-court representation, and generates a downloadable coach-style performance report.

-
Tech Stack: Python · PyTorch · OpenCV · YOLO · ByteTrack · Streamlit · SAM · Plotly · Docker · CUDA TrackNet · CI/CD Pipeline · Homography · Body Poses estimation · 3D Motion Trajectories
-
Demo: Live Demo | CV. Pipeline Video | Dashboard Video
This project focuses on semantic segmentation using the BDD100K dataset, a large-scale, diverse dataset for autonomous driving. The main objective is to accurately segment and identify various objects in street scenes, which is important for improving the AI perception vision of autonomous vehicles.
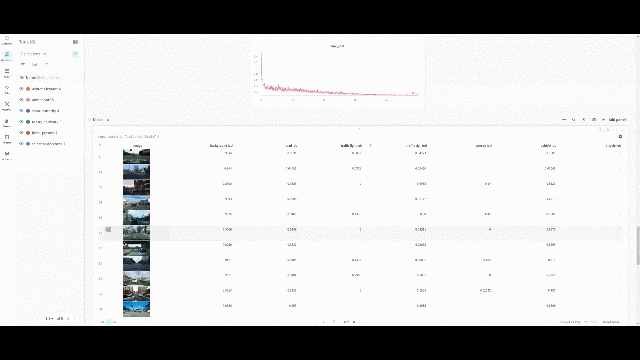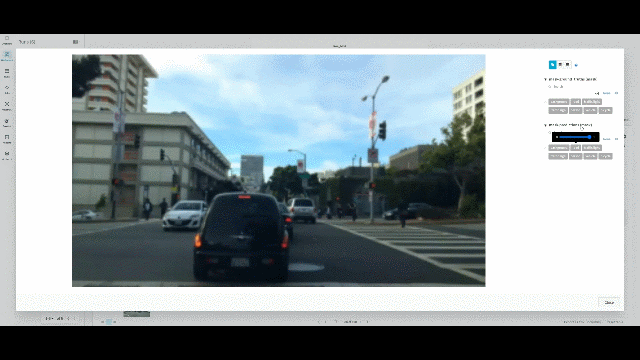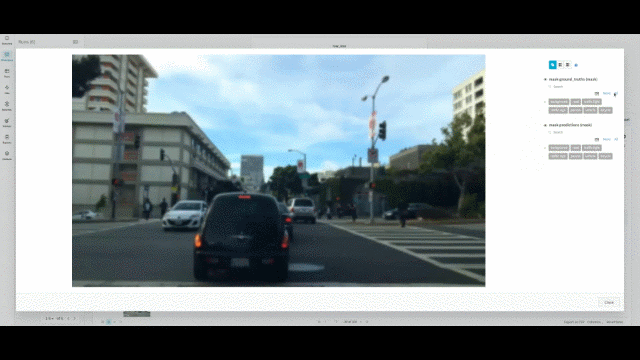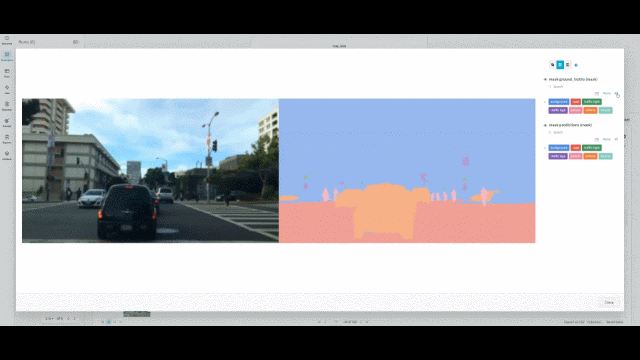
- Tech Stack: PyTorch · Fastai · Semantic Segmentation · Hyperparamter Tunning · Weights & Biases
An end-to-end workflow for multi-label brain tumor segmentation from 3D multimodal MRI scans. The project targets segmentation of glioma subregions (tumor core, whole tumor, enhancing tumor) using a 3D SegResNet model.
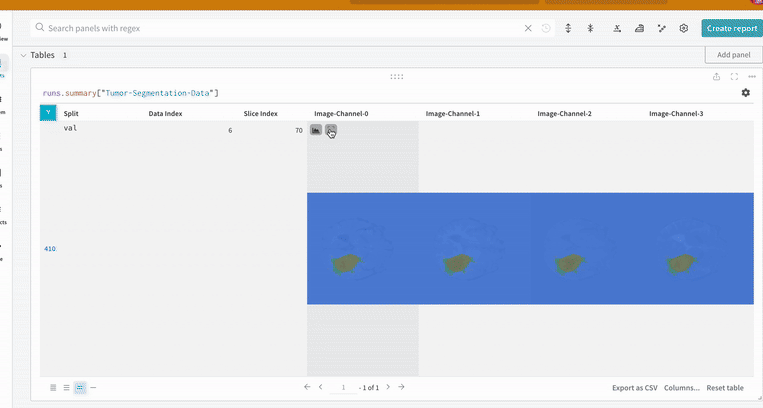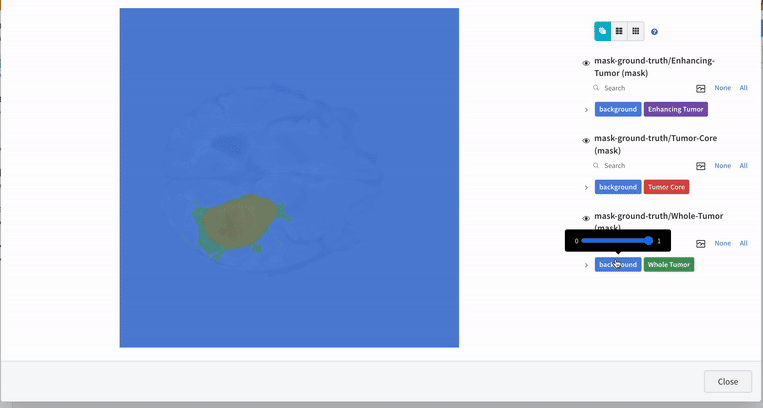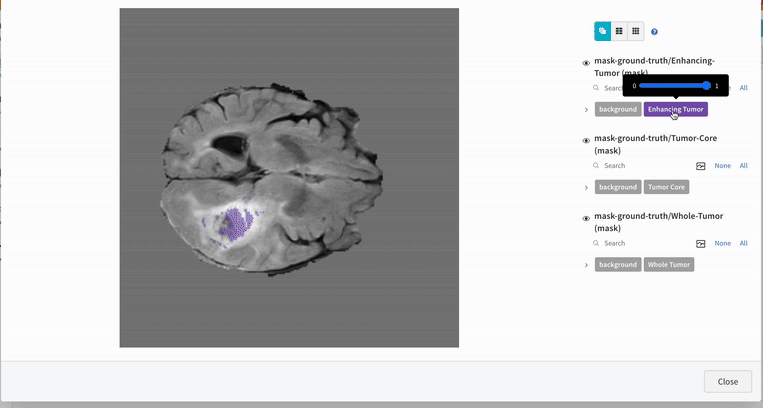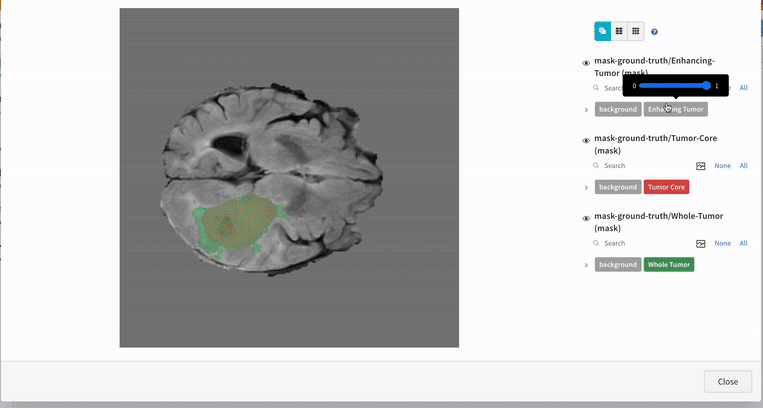
Tech Stack: PyTorch · MONAI · 3D SegResNet · Multi-modal MRI 3D Medical Image Transforms · Sliding Window Inference · Experiment Tracking (W&B)
This repository contains a curated set of Jupyter notebooks demonstrating core computer vision and vision–language capabilities using VLM foundation models. The notebooks progress from offline image understanding tasks to a realtime webcam application that performs image captioning and image classification on live video streams.
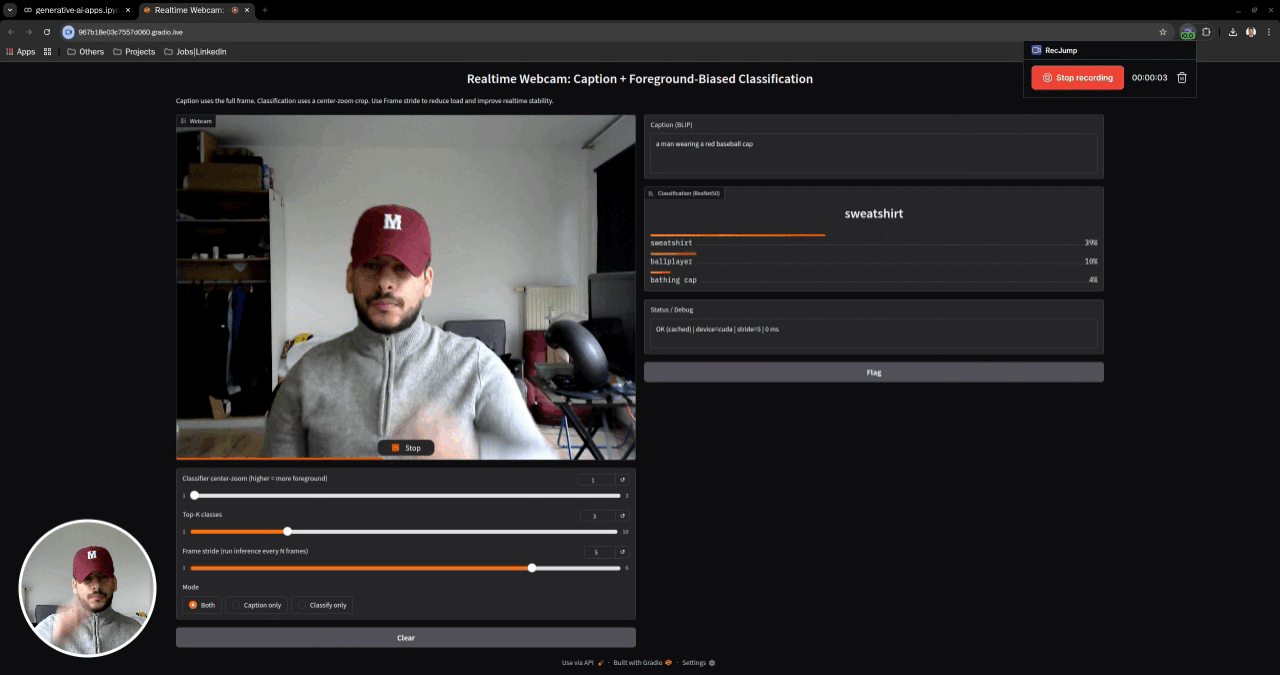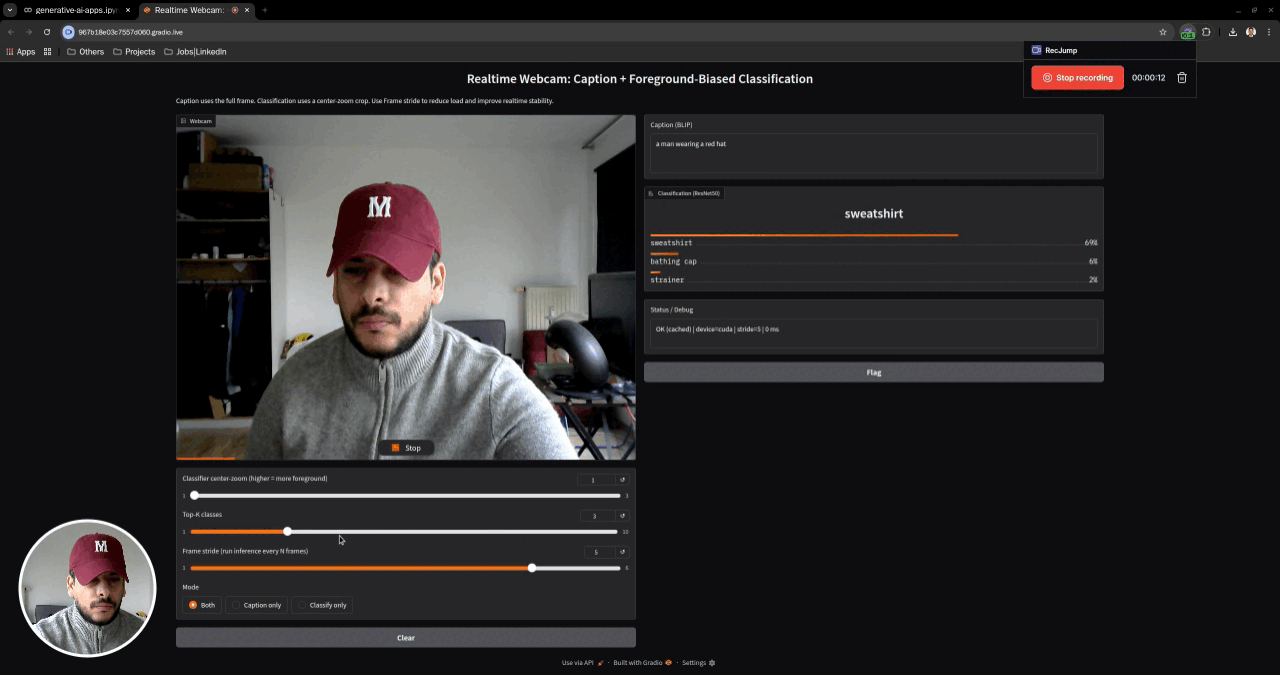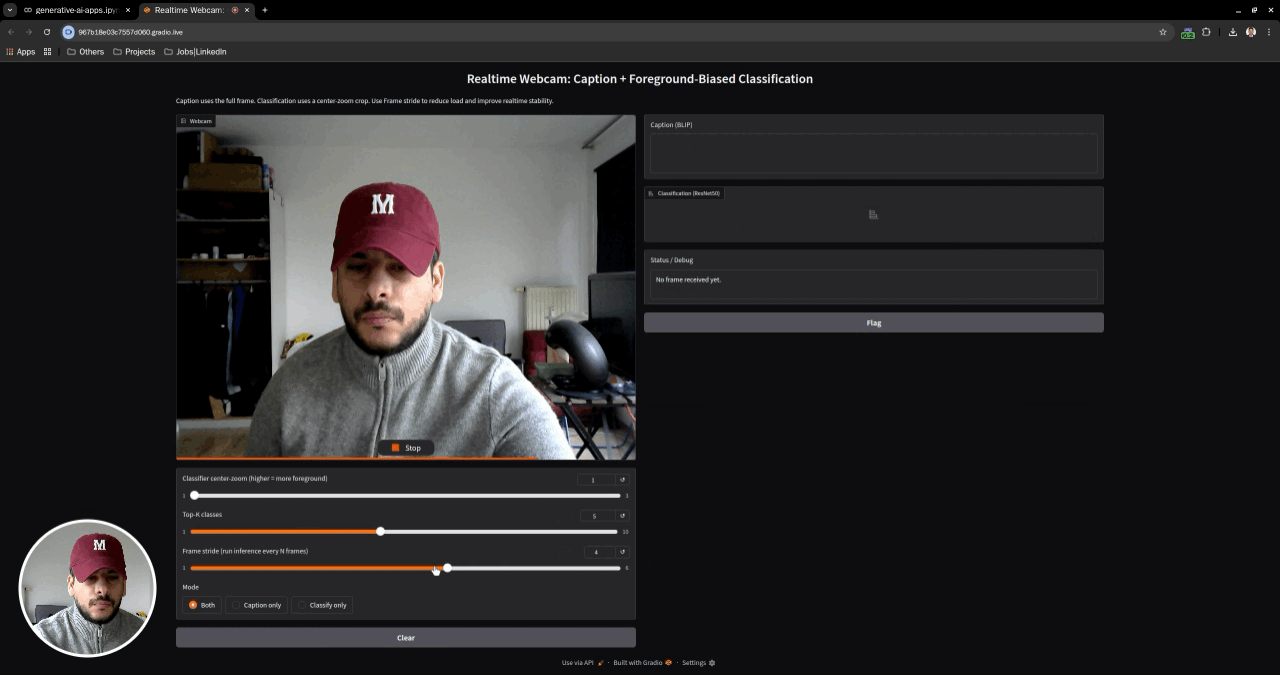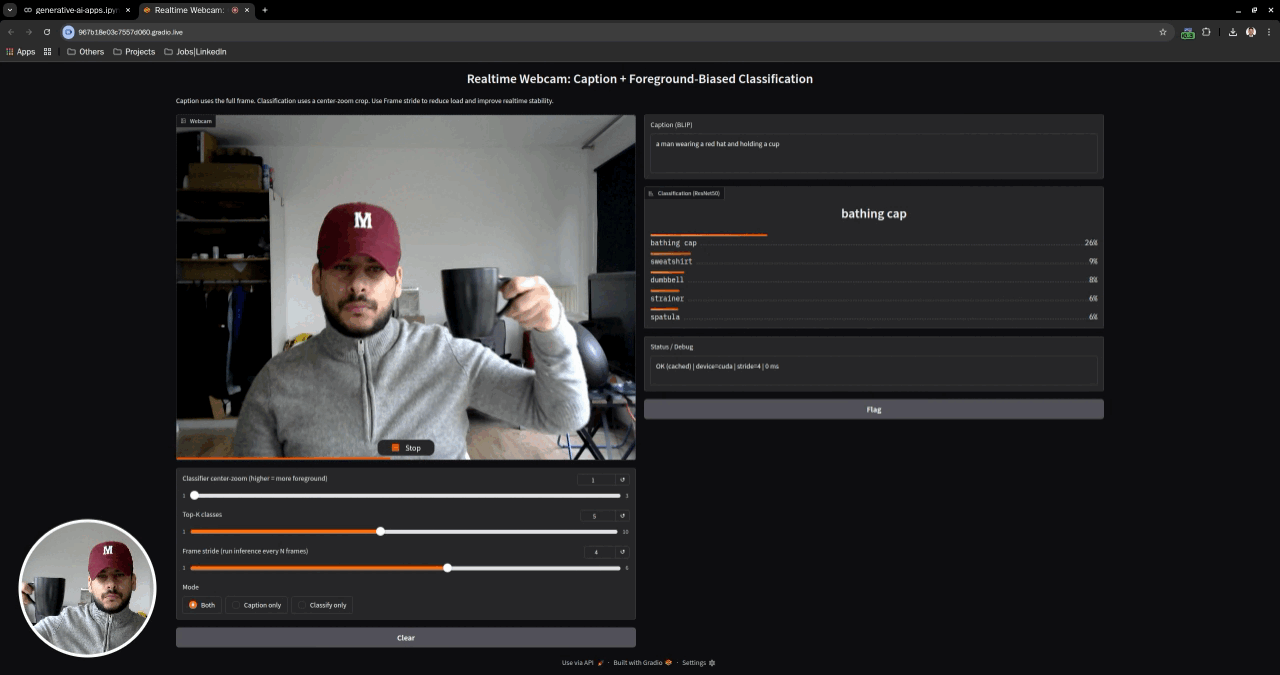
- Tech Stack: PyTorch · Torchvision · Hugging Face Transformers · Gradio · PIL · VLM · Realtime inference
🎙️ AI Conversational Agent (Ongoing)
This AI Agent is more than just a chatbot. It is real-time voice/text interaction, LLM-powered reasoning, and a digital human conversational model.
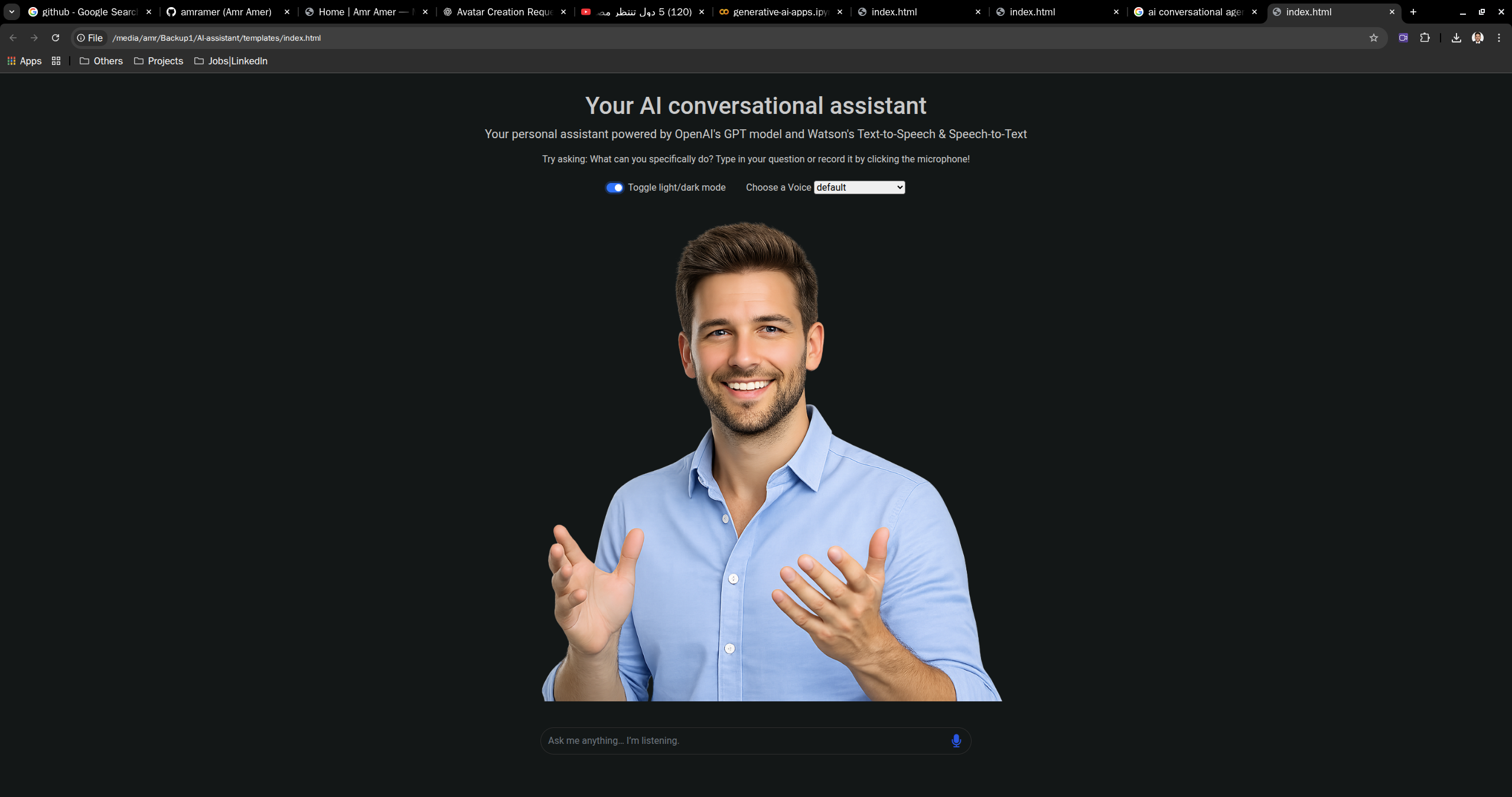
- Tech Stack: Python · OpenAI GPT · Speech-to-Text · Text-to-Speech · HTML · CSS · JavaScript · Bootstrap · jQuery
For more details about my work and projects, visit my portfolio website.
| Area | Skills & Tools |
|---|---|
| Computer Vision | Object Detection, Segmentation, Tracking, Video Motion Analysis, Digital Human Models |
| Models & Frameworks | PyTorch, TensorFlow, OpenCV, YOLO, Vision Transformers (ViT), Supervision |
| Training & Evaluation | Transfer Learning, Hyperparameter Optimization, Weights & Biases, TensorBoard |
| Deployment | Docker, AWS (EC2 GPU), Streamlit, Batch & Real-time Inference |
| Software Engineering | Python, C++, Object-Oriented Design, Git, Debugging, Unit Testing |