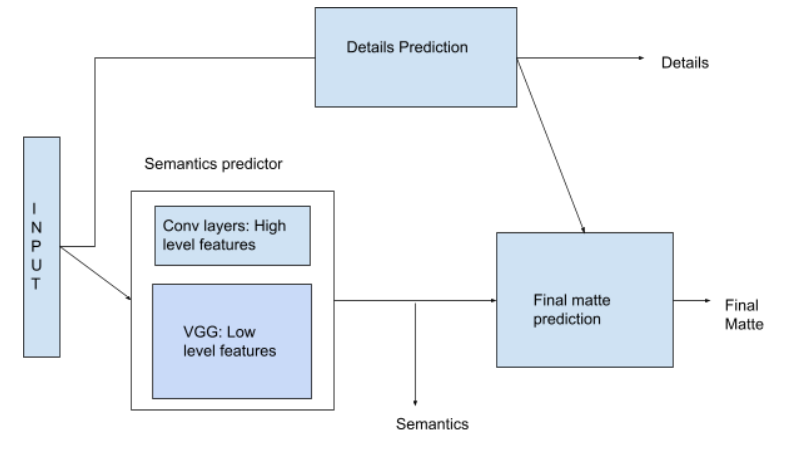
Final submission of course project, MODNet: Real-Time Trimap-Free Portrait Matting via Objective Decomposition.
Saved model could not be uploaded due to file size>25MB.
Drive link:- https://drive.google.com/file/d/12Hx62JvC0ku-lIOABruaFHPj3fXM8Gs8/view?usp=sharing
class Sp(nn.Module):
def __init__(self,vgg16,M=4):
super(Sp,self).__init__()
self.vgg = vgg16
self.conv1 = nn.Conv2d(3,32,3,padding= 'same')
self.act1 = nn.Sigmoid()
self.max1 = nn.MaxPool2d(4)
self.conv2 = nn.Conv2d(32,32,3,padding= 'same')
self.act2 = nn.Sigmoid()
self.max2 = nn.MaxPool2d(2)
self.upsample1 = nn.Upsample(scale_factor = 2) #16x16
self.convtrans1 = nn.ConvTranspose2d(512,128,(3,3),padding = 1)
self.sig1 = nn.Sigmoid()
self.upsample2 = nn.Upsample(scale_factor = 2) #32x32
self.convtrans2 = nn.ConvTranspose2d(160,1,(3,3),padding = 1)
self.sig2 = nn.Sigmoid()
#self.thresh = nn.Threshold(0.5,0)
def forward(self,X):
#pretrained vgg for low level features
V = self.vgg(X)
#high level features
X = self.conv1(X)
X = self.act1(X)
X = self.max1(X)
X = self.conv2(X)
X = self.act2(X)
I = self.max2(X)
X = self.upsample1(V)
X = self.convtrans1(X)
X = self.sig1(X)
X = self.upsample2(X)
#high + low level features
X = torch.cat([X,I],1)
X = self.convtrans2(X)
X = self.sig2(X)
return X
class Sp(nn.Module):
def __init__(self,vgg16,M=4):
super(Sp,self).__init__()
self.vgg = vgg16
self.conv1 = nn.Conv2d(3,32,3,padding= 'same')
self.act1 = nn.Sigmoid()
self.max1 = nn.MaxPool2d(4)
self.conv2 = nn.Conv2d(32,32,3,padding= 'same')
self.act2 = nn.Sigmoid()
self.max2 = nn.MaxPool2d(2)
self.upsample1 = nn.Upsample(scale_factor = 2) #16x16
self.convtrans1 = nn.ConvTranspose2d(512,128,(3,3),padding = 1)
self.sig1 = nn.Sigmoid()
self.upsample2 = nn.Upsample(scale_factor = 2) #32x32
self.convtrans2 = nn.ConvTranspose2d(160,1,(3,3),padding = 1)
self.sig2 = nn.Sigmoid()
#self.thresh = nn.Threshold(0.5,0)
def forward(self,X):
#pretrained vgg for low level features
V = self.vgg(X)
#high level features
X = self.conv1(X)
X = self.act1(X)
X = self.max1(X)
X = self.conv2(X)
X = self.act2(X)
I = self.max2(X)
X = self.upsample1(V)
X = self.convtrans1(X)
X = self.sig1(X)
X = self.upsample2(X)
#high + low level features
X = torch.cat([X,I],1)
X = self.convtrans2(X)
X = self.sig2(X)
return X
class Fp(nn.Module):
def __init__(self):
super(Fp,self).__init__()
self.upsample1 = nn.Upsample(scale_factor = 2)
self.convtrans1 = nn.ConvTranspose2d(1,16,(3,3),padding = 1)
self.act1 = nn.Sigmoid()
self.upsample2 = nn.Upsample(scale_factor = 2)
self.convtrans2 = nn.ConvTranspose2d(24,16,(3,3),padding = 1)
self.act2 = nn.Sigmoid()
self.upsample3 = nn.Upsample(scale_factor = 2)
self.convtrans3 = nn.ConvTranspose2d(16,1,(3,3),padding = 1)
self.sig1 = nn.Sigmoid()
#self.thresh = nn.Threshold(0.5,0)
def forward(self,S,D):
S = self.upsample1(S)
S = self.convtrans1(S)
S = self.act1(S)
S = self.upsample2(S)
S = torch.cat([S,D],1)
S = self.convtrans2(S)
S = self.act2(S)
S = self.upsample3(S)
S = self.convtrans3(S)
S = self.sig1(S)
#S = self.thresh(S)
return S
class MODNet(nn.Module):
def __init__(self,vgg16):
super(MODNet,self).__init__()
self.S = Sp(vgg16)
self.D = Dp()
self.F = Fp()
self.max1 = nn.MaxPool2d(2)
self.upsample1 = nn.Upsample(scale_factor = 2)
def forward(self,X):
I = X
X = self.S(X)
I = self.max1(I)
D = self.D(I,X)
F = self.F(X,D)
details = self.D.getDp()
return [F,X,details]
To use the model to remove background from your live camera feed, download the saved model from above mentioned drive link. Store it in the same location as MODNET virtualcam.py and run the python file. This however requires you to have OBS virtual camera to be installed in your system.
https://obsproject.com/download
https://drive.google.com/file/d/12Hx62JvC0ku-lIOABruaFHPj3fXM8Gs8/view?usp=sharing