Our submission to the Algonauts 2023 challenge.
Challenge Leaderboard username: hosseinadeli
Adeli, H., Minni, S., & Kriegeskorte, N. (2023). Predicting brain activity using Transformers. bioRxiv, 2023-08. [bioRxiv]
Please cite our work by using the following BibTeX entry.
@article{adeli2023predicting,
title={Predicting brain activity using Transformers},
author={Adeli, Hossein and Minni, Sun and Kriegeskorte, Nikolaus},
journal={bioRxiv},
pages={2023--08},
year={2023},
publisher={Cold Spring Harbor Laboratory}
}Hossein Adeli
ha2366@columbia.edu
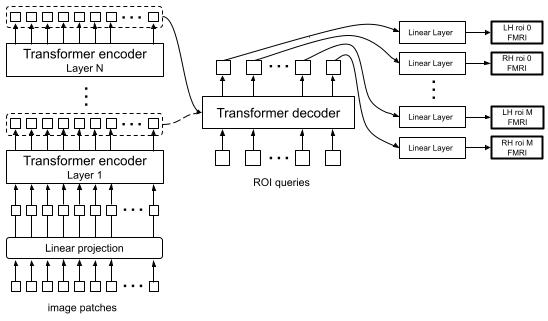
Instead of using ROI based decoder queries, I am using a query for each voxel so there is no need for brain areas mapping. That means:
- You need a big GPU for this
- The model has around 40K decoder tokens (sum of all voxels in the left and the right hemispheres), one for each voxel. So there can be no self-attention operation on the decoder side as the attention matrix would be prohibitively large, just cross attending to the encoder features patches
- The Batch size would have to be very small, I can only go up to 2 on L40 gpus before running into memory issues.
It improves accuracy across the board.

You can train the model using the code below.
python main.py --run 1 --subj 1 --enc_output_layer 1 --readout_res 'streams_inc'The model can accept many parameters for the run. Here the run number is given, the subject number, which encoder layer output should be fed to the decoder ([-1] in this case), and what type of queries should the transformer decoder be using.
With 'streams_inc', all the vertices are predicted using queries for all the streams. You can use the visualize_results.ipynb to see the results after they are saved.
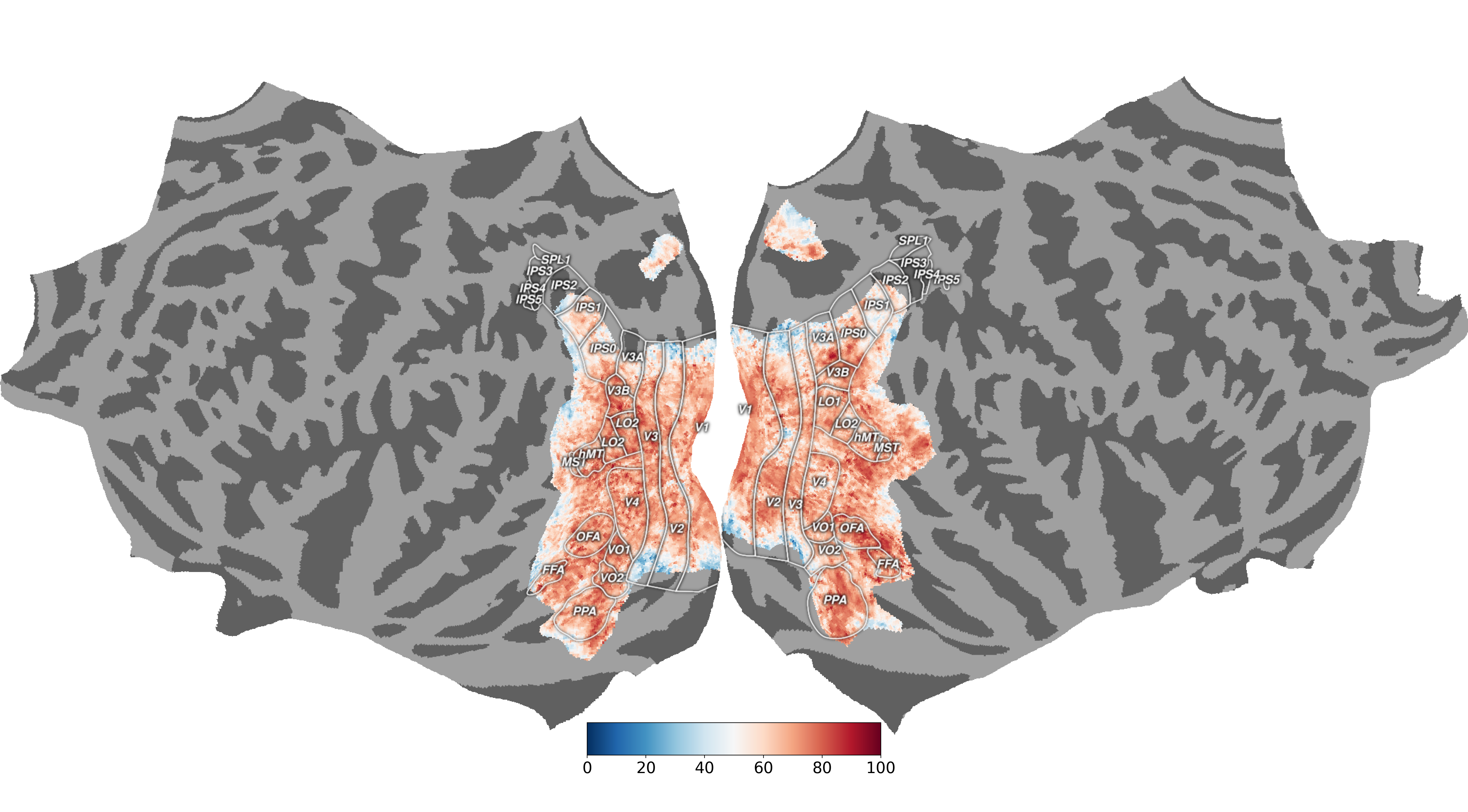
Results from a sample run for subj 1:
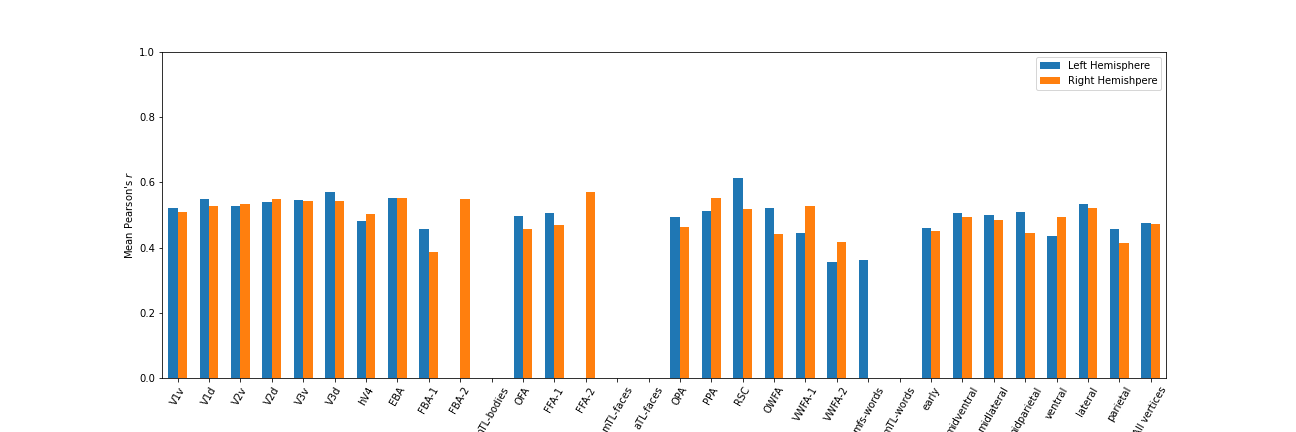
In order to train the model using a lower level features from the encoder and to focus on early visual areas:
python main.py --run 1 --subj 1 --enc_output_layer 8 --readout_res 'visuals'Results from a sample run for subj 1:
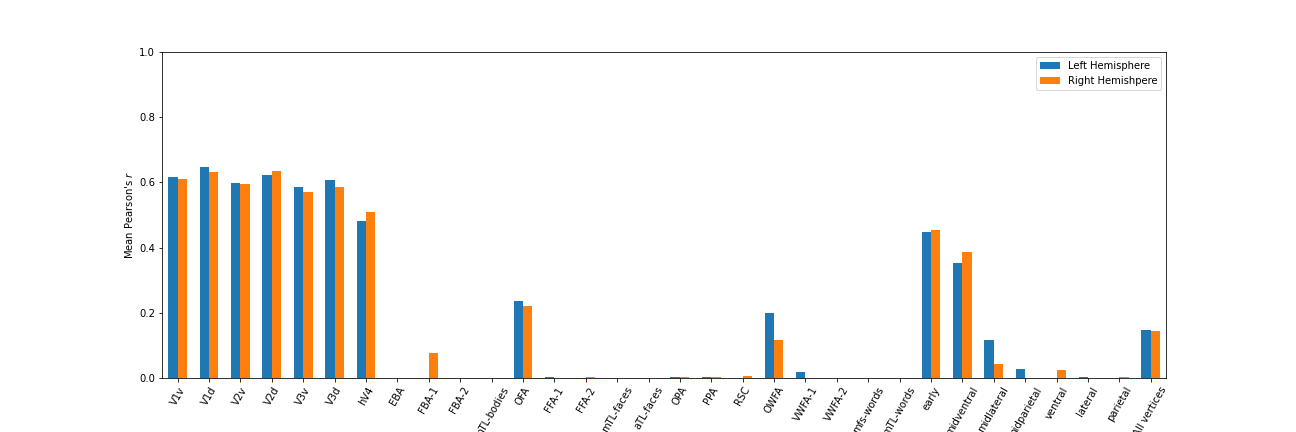
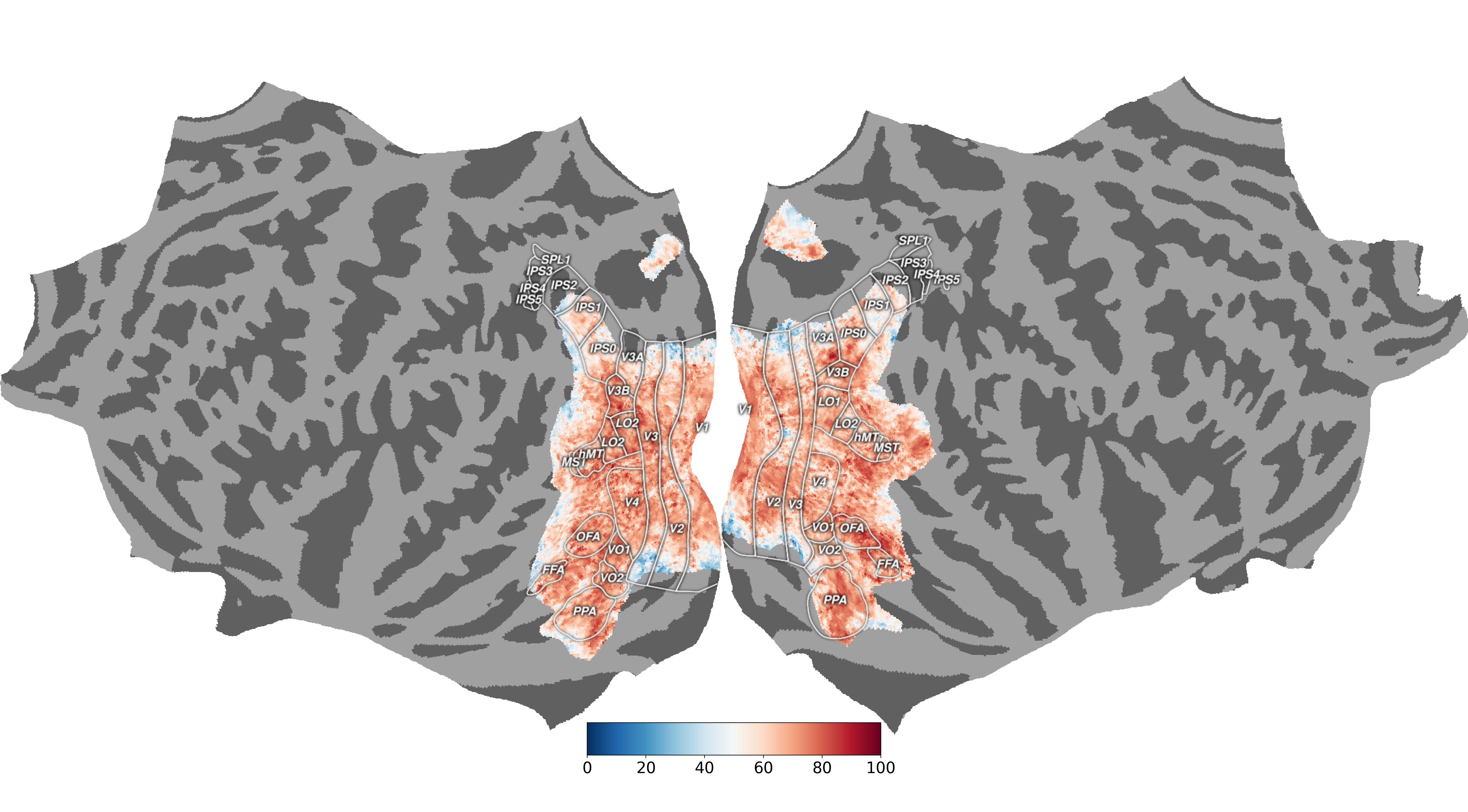
Final prediction results (from http://algonauts.csail.mit.edu/visualizations_2023/02_hosseinadeli.png):
{kind=link}
Download model checkpoint from this google drive folder:
python main.py --run 1 --subj 1 --enc_output_layer 1 --readout_res 'faces' --save_model 1Save the model check point. attention_maps.ipynb can then be used to visualize the attention weights for the decoder queries (where each query attends to in the image in order to predict an ROI).


The following repositories were used, either in close to original form or as an inspiration: