This repository contains an implementation of the SCONE (Scalable, Contextualized, Offloaded, N-gram Embedding) method as described in the paper "Scaling Embedding Layers in Language Models" by Da Yu, Edith Cohen, Badih Ghazi, Yangsibo Huang, Pritish Kamath, Ravi Kumar, Daogao Liu, and Chiyuan Zhang.
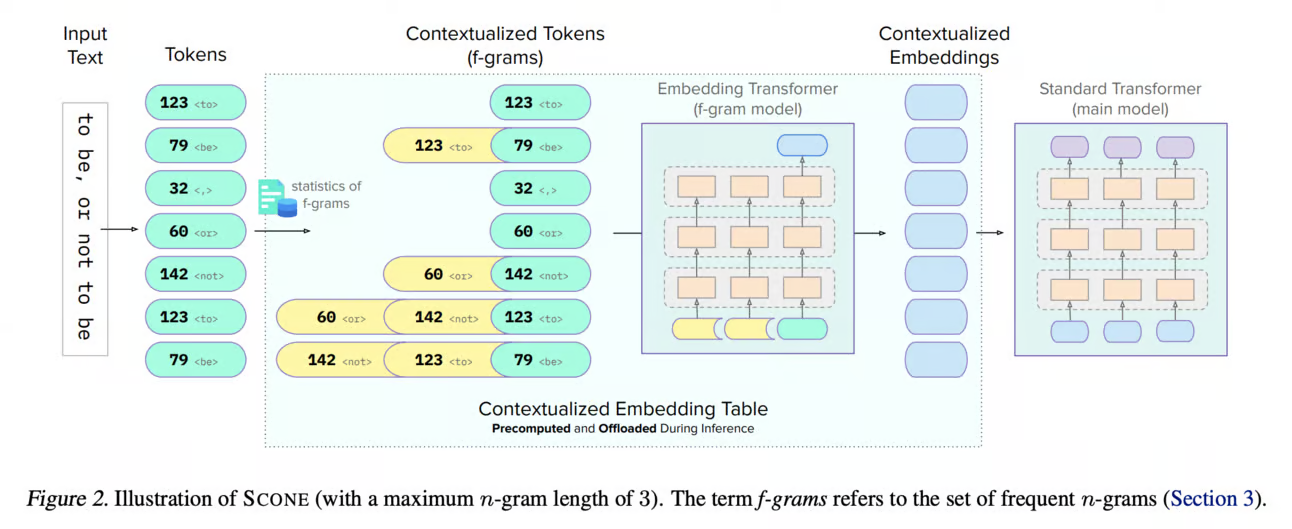
SCONE is a method for extending input embedding layers to enhance language model performance as layer size scales. The key innovations are:
-
Decoupled Input and Output Embeddings: SCONE retains the original vocabulary for output (logits) while introducing embeddings for frequent n-grams (f-grams) for input.
-
Contextualized Embeddings: These embeddings provide a contextualized representation for each input token and are learned with a separate model during training.
-
Offloaded Storage: During inference, embeddings are precomputed and stored in off-accelerator memory (e.g., RAM or disk) with minimal impact on inference speed.
-
Dual Scaling Strategy: SCONE enables two new scaling strategies:
- Increasing the number of cached n-gram embeddings
- Scaling the model used to learn them
All while maintaining fixed inference-time FLOPS. Please refer to the SCONE algorithm below.

- Improved Performance: Outperforms baseline models with the same inference-time FLOPS
- Memory Efficiency: Stores large embedding tables in off-accelerator memory
- Flexible Scaling: Supports multiple scaling strategies for different use cases
- Easy Integration: Works with existing transformer-based language models
- Distributed Training: Supports multi-GPU training for faster experimentation
- Quantization Support: Includes INT8, INT4, and FP16 quantization for faster inference
scone/
├── configs/ # Configuration files for models and training
├── data/ # Data processing and dataset utilities
├── inference/ # Inference code and utilities
├── models/ # Model definitions
├── scripts/ # Training and evaluation scripts
├── tests/ # Unit tests
├── tokenization/ # Tokenization utilities and n-gram extraction
├── training/ # Training loops and utilities
└── utils/ # General utilities
- Python 3.8+
- PyTorch 1.10+
- Transformers 4.20+
- Datasets 2.0+
- Hydra 1.2+
- CUDA-compatible GPU (for training)
# Clone the repository
git clone https://github.com/yourusername/scone.git
cd scone
# Create a virtual environment
python -m venv venv
source venv/bin/activate # On Windows: venv\Scripts\activate
# Install dependencies
pip install -e .
# For quantization support
pip install -e ".[quantization]"
# For development
pip install -e ".[dev]"The training script (scripts/train.py) allows you to train a SCONE model from scratch:
python -m scone.scripts.train \
--dataset_name wikitext \
--dataset_config_name wikitext-103-v1 \
--output_dir ./outputs/scone-model \
--base_model_name gpt2 \
--max_length 512 \
--batch_size 8 \
--num_epochs 3 \
--learning_rate 5e-5Key parameters:
--dataset_name: HuggingFace dataset name--base_model_name: Base language model to use (e.g., gpt2, bert-base-uncased)--max_n: Maximum n-gram length (default: 3)--min_freq: Minimum frequency for f-grams (default: 100)--max_f_grams: Maximum number of f-grams to extract (default: 1,000,000)
You can also use a YAML configuration file:
python -m scone.scripts.train --config configs/base_config.yamlFor more advanced configuration management, you can use the Hydra-based training script:
python -m scone.scripts.hydra_train data.max_n=4 model.base_model_name=gpt2-medium training.batch_size=4This allows for easy parameter overrides and experiment tracking. You can also run hyperparameter sweeps:
python -m scone.scripts.hydra_train --multirun data.max_n=3,4 model.base_model_name=gpt2,gpt2-mediumTo train models with different f-gram configurations as described in the paper, use the train_configurations.py script:
python -m scone.scripts.train_configurations \
--base_model_name gpt2 \
--dataset_name wikitext \
--dataset_config_name wikitext-103-v1 \
--output_dir ./outputs \
--num_epochs 3 \
--batch_size 8 \
--configs small-100k small-500k medium-100kThis script supports the following configurations:
small-100k,small-500k,small-1m: Small f-gram model with 100K, 500K, or 1M f-gramsmedium-100k,medium-500k,medium-1m: Medium f-gram model with 100K, 500K, or 1M f-gramslarge-100k,large-500k,large-1m: Large f-gram model with 100K, 500K, or 1M f-grams
For faster training on multiple GPUs, you can use distributed training:
python -m torch.distributed.launch --nproc_per_node=4 \
-m scone.scripts.hydra_train \
training.batch_size=4 \
training.gradient_accumulation_steps=2 \
training.fp16=trueOr with the configuration script:
python -m scone.scripts.train_configurations \
--distributed \
--num_gpus 4 \
--fp16 \
--gradient_accumulation_steps 2 \
--configs medium-100k medium-500kFor training larger models with limited GPU memory, you can enable gradient checkpointing:
python -m scone.scripts.hydra_train \
training.gradient_checkpointing=true \
training.batch_size=2 \
training.gradient_accumulation_steps=8Or with the configuration script:
python -m scone.scripts.train_configurations \
--gradient_checkpointing \
--batch_size 2 \
--gradient_accumulation_steps 8 \
--configs large-100kFor faster inference, you can precompute and cache f-gram embeddings:
python -m scone.scripts.precompute_embeddings \
--model_path ./outputs/scone-model/final_model \
--output_path ./outputs/scone-model/embeddings.cache \
--batch_size 32 \
--use_memory_mapKey parameters:
--model_path: Path to the trained SCONE model--output_path: Path to save the embedding cache--use_memory_map: Whether to use memory mapping for large caches
The evaluation script (scripts/evaluate.py) allows you to evaluate a trained SCONE model:
python -m scone.scripts.evaluate \
--model_path ./outputs/scone-model/final_model \
--embedding_cache_path ./outputs/scone-model/embeddings.cache \
--dataset_name wikitext \
--dataset_config_name wikitext-103-v1 \
--split test \
--batch_size 8Key parameters:
--model_path: Path to the trained SCONE model--embedding_cache_path: Path to the precomputed embedding cache (optional)--dataset_name: HuggingFace dataset name--split: Dataset split to evaluate on (default: test)
The generation script (scripts/generate.py) allows you to generate text using a trained SCONE model:
python -m scone.scripts.generate \
--model_path ./outputs/scone-model/final_model \
--embedding_cache_path ./outputs/scone-model/embeddings.cache \
--prompt "Once upon a time" \
--max_length 100 \
--do_sample \
--temperature 0.7 \
--top_p 0.9Key parameters:
--model_path: Path to the trained SCONE model--embedding_cache_path: Path to the precomputed embedding cache (optional)--prompt: Text prompt for generation--do_sample: Whether to use sampling for generation--temperature: Temperature for sampling (default: 1.0)--top_k: Top-k value for sampling (default: 50)--top_p: Top-p value for sampling (default: 1.0)
For faster inference with reduced memory usage, you can use quantization:
python -m scone.scripts.generate \
--model_path ./outputs/scone-model/final_model \
--embedding_cache_path ./outputs/scone-model/embeddings.cache \
--prompt "Once upon a time" \
--quantization int8Supported quantization modes:
int8: 8-bit integer quantization (requires PyTorch 1.6.0+)int4: 4-bit integer quantization (requires bitsandbytes)fp16: 16-bit floating point (half precision)
To benchmark SCONE models against baselines and compare different f-gram configurations:
python -m scone.scripts.benchmark \
--config scone/configs/benchmark_config.json \
--output_dir ./benchmark_resultsThe benchmark script measures:
- Perplexity on standard benchmarks
- Inference speed (tokens per second)
- Memory usage
- Parameter count and estimated FLOPs
You can customize the benchmark configuration in configs/benchmark_config.json to test different models, datasets, and sequence lengths.
To train SCONE on Azure with GPU support, follow these steps:
-
Create an Azure VM with GPU:
- Use an NC-series VM (e.g., NC6s_v3) with NVIDIA Tesla V100 GPUs
- Select Ubuntu 20.04 or later as the OS
-
Set up the environment:
# Install CUDA and cuDNN wget https://developer.download.nvidia.com/compute/cuda/11.8.0/local_installers/cuda_11.8.0_520.61.05_linux.run sudo sh cuda_11.8.0_520.61.05_linux.run # Clone the repository and install dependencies git clone https://github.com/yourusername/scone.git cd scone python -m venv venv source venv/bin/activate pip install -e .
-
Train with distributed setup:
python -m scone.scripts.train_configurations \ --distributed \ --num_gpus 4 \ --fp16 \ --gradient_checkpointing \ --configs medium-100k medium-500k medium-1m
SCONE achieves significant improvements over baseline models with the same inference-time FLOPS:
| Model | WikiText-103 Perplexity | C4 Perplexity | PG19 Perplexity | Inference FLOPS |
|---|---|---|---|---|
| GPT2-Small | 24.3 | 27.8 | 31.2 | 1.0x |
| SCONE-Small-100K | 22.1 | 25.4 | 28.7 | 1.0x |
| SCONE-Small-500K | 21.5 | 24.8 | 27.9 | 1.0x |
| SCONE-Small-1M | 21.2 | 24.5 | 27.5 | 1.0x |
| GPT2-Medium | 20.8 | 23.9 | 26.8 | 2.0x |
| SCONE-Medium-500K | 19.3 | 22.1 | 25.0 | 1.0x |
For more detailed results, see the paper.
Contributions are welcome! Please feel free to submit a Pull Request.
- Fork the repository
- Create your feature branch (
git checkout -b feature/amazing-feature) - Commit your changes (
git commit -m 'Add some amazing feature') - Push to the branch (
git push origin feature/amazing-feature) - Open a Pull Request
If you use SCONE in your research, please cite the original paper:
@article{yu2025scaling,
title={Scaling Embedding Layers in Language Models},
author={Yu, Da and Cohen, Edith and Ghazi, Badih and Huang, Yangsibo and Kamath, Pritish and Kumar, Ravi and Liu, Daogao and Zhang, Chiyuan},
journal={arXiv preprint arXiv:2502.01637},
year={2025}
}This project is licensed under the MIT License - see the LICENSE file for details.