Machine Learning Approach for Identifying Suspicious Uniform Resource Locators (URLs) on Reddit Social Network
This repository is the implementation of a Reddit post crawler and phish URL identification using VirusTotal.
To install requirements:
- Visual Studio 2015 or higher
- Microsoft SQL Server
- Dapper Micro-ORM
- FileHelpers
- LumenWorksCsvReader
- Microsoft.Data.SqlClient
- Newtonsoft.json
- VirusTotalNet
- pandas
- praw
- numpy
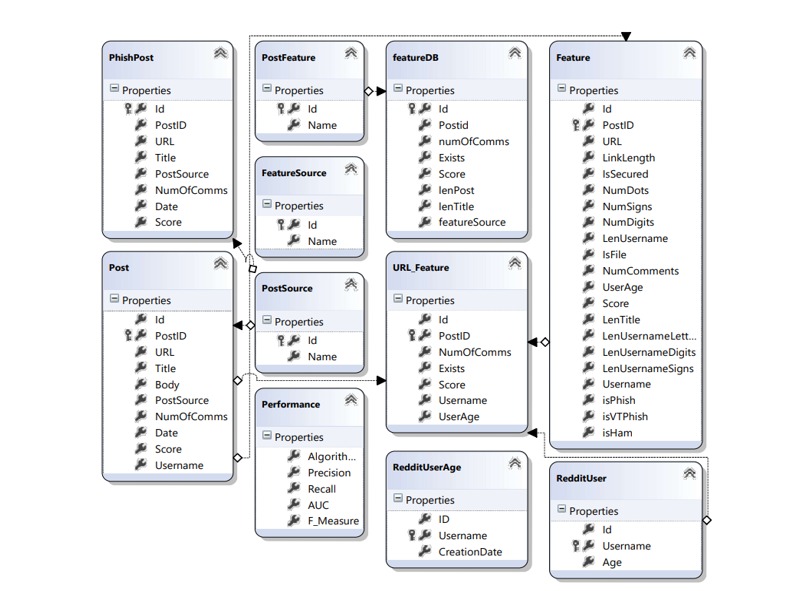
📋Move Virual environment folder 'Reddit Post Crawler' (containing /reddit-crawler-env) to the /bin/Debug folder ########## Create Database table as defined by this Schema
- Create a New reddit app
- Open praw_scrapper.py file in the virual environment (Reddit Post Crawler) and add app credentials to initialize praw
- Activate virtual environment and run 'praw_scrapper.py'
- After crawling for posts and saved to new_all_posts.csv (**new and **all are named to indicate the filter values of the scrapper, changeable in praw_scrapper.py)
- Add microsoft server connection credentials to App.config
- Build and Run the Visual Studio project to start indexing and validating posts
Resulting datasets and processed dataset here